


- Amazon
- Amazon SageMaker
Healthcare Product Supplier Launches Feature Store for Improved Data Science Workflow



This company, an industry-leading supplier of products, platforms, and services for the healthcare industry, came to Wavicle to improve data access and streamline data science workflows in Databricks.
Wavicle brought development-ready data into Databricks through ingestion work and developed a process to ensure consistent feature calculations, nomenclature, and availability for models in different parts of the business: a feature store. The feature store reduces the time spent on preprocessing, feature engineering, and data blending and allows models to easily convert from development to production.
Wavicle taught this healthcare product supplier about the feature store, implemented a minimum viable product (MVP) in Databricks, and provided a framework for further feature store usage in Databricks.
Challenges accessing clean, defined data and high time-to-model data turnover rate
When building models, data scientists on the healthcare product supplier’s team did not always know where data was located or who the relevant data experts were. Data that had been used in one data science project might be required for a new project, but data scientists were hesitant to use the cleaned data because they lacked visibility to how the data had been sourced and cleaned. Data definitions were not always well documented, and models suffered delays moving from experimentation to production because the underlying data sources were not production ready.
This created rework for data engineers, discouraged experimentation with new data sources within the data science team, and delayed model deployment. The team needed a better way of understanding and accessing their data that could supply clean, defined data for data science projects and streamline workflows moving forward.
Solving data challenges with a robust feature store
Wavicle’s data and analytics experts helped the healthcare supply company improve their data science workflows through a multi-step process to implement a feature store.
Research and education
The healthcare product supplier had originally engaged Wavicle to bring the data underlying its machine learning models into Databricks. The Wavicle team was aware of the feature store capabilities in Databricks – powered by the Unity Catalog – and consequently identified that the feature store could address many of the company’s challenges.
Wavicle created an overview of the feature store benefits and an architecture diagram that served as a guidepost throughout the project. The customer’s team used this information to assess the importance of the feature store and decided to prioritize a feature store MVP along with the Databricks ingestion work.
 Pilot implementation
Pilot implementation
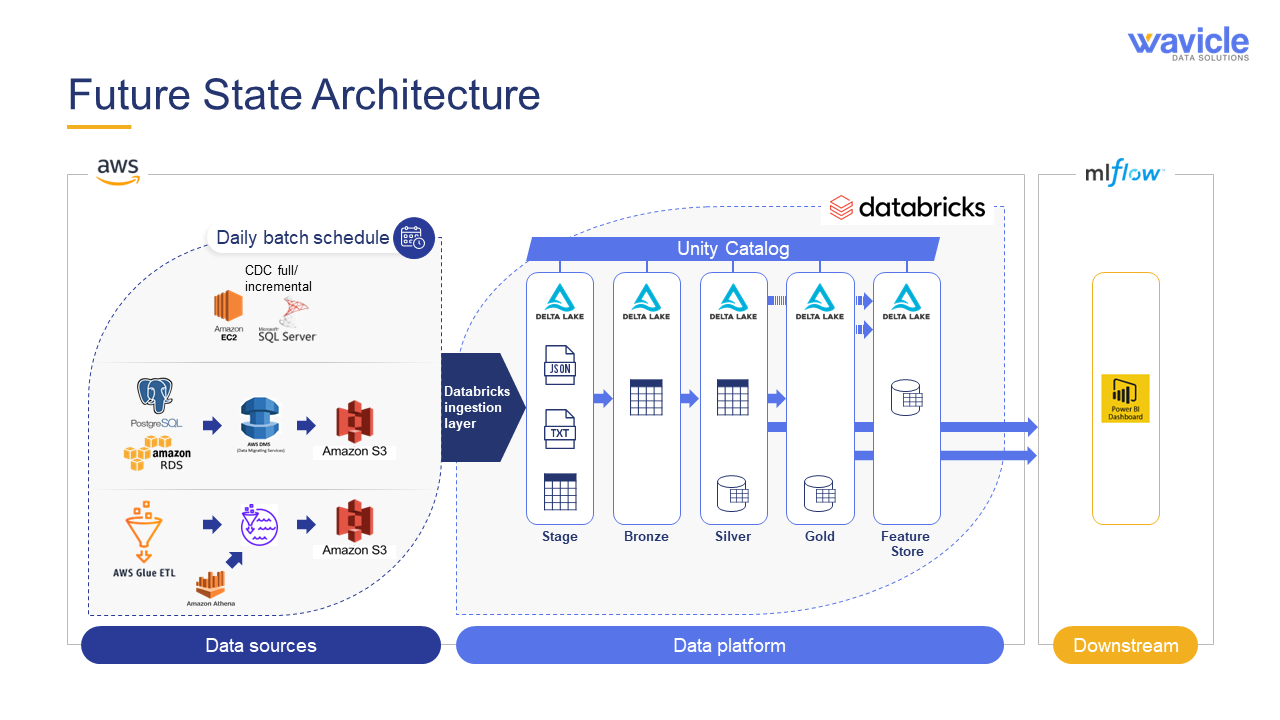
Pipelines had been identified for ingestion to the silver layer in Databricks for the highest priority models. Although these data pipelines had business definitions associated with them, the data did not yet meet the high standard of a feature store, which allows for consistent use of features across domains and for models that were in production. The healthcare product supplier’s platform engineering team identified the highest-impact pipelines that should be ingested to the feature store.
These pipelines were known as the pilot feature MVP. The MVP pipelines were brought into the feature store using the pertinent business definitions.
In addition, the MVP feature store used Unity Catalog within Databricks to handle critical data governance needs. Unity Catalog was used to apply governance to the machine learning models and to provide the basis for building data quality into the data pipeline process. Wavicle’s team leveraged Unity Catalog’s flexible platform to utilize several third-party applications for help with advanced profiling and data quality workflows and to provide a more automated data governance approach. The features that had been used for the pilot also now had clear business definitions and traceability.
The pilot provided valuable information for the customer:
- Data engineers (DataOps): The data engineers had a documented, effective process for migrating features from the silver layer to the feature store in Databricks. This meant that they could accurately plan for additional features that must be added to the feature store.
- Data scientists: The data scientists now had a set of features that could be called from a Databricks notebook or an Amazon SageMaker notebook. This helped them evaluate the best environment for machine learning projects in Databricks.
MVP impact
The feature store MVP opened the door to further feature store implementations in Databricks. The healthcare product supplier’s team was now aware of how the feature store would speed up model building and deployment to production. This effort included the establishment of standard procedures and documentation for standardization and reference.
The MVP was a critical step in more widespread use of the feature store, which would address many of the problems that the customer was facing with machine learning engineering. Sourcing data for models from the feature store now provides clean, well-defined data that easily transitions from experimentation to production. This increases development velocity by providing engineers with a more limited, modern architecture.
Feature store benefits
Defined below are the benefits of the feature store when implemented beyond the MVP:
- Model development: The feature store increases productivity for the data science team when training models. Because the business definitions are established, data scientists no longer need to find the subject matter expert for the data source to understand what a feature represents. The feature store thus reduces the time delay in coordinating between the subject matter expert and the data scientist when identifying the data. Multiple data scientists can use the same data without repeating the time-consuming exploration piece of the data understanding process.
- Productionizing model: When the model moves from training to production, the feature store can be utilized as the same source for both. This eliminates rework when launching the model into production and promotes a more time-efficient deployment while still using well-commented data.
- Data science and BI working together: The feature store has high-quality, well-documented data. Even though the ingestion work was planned to meet use cases of the data science team, the data can be used for reporting across the various organizations beyond data science. Cross-departmental work is a major benefit for the entire organization as it will implement trusted data for wider reporting and maximize the business insights and value generated by the data.
An improved customer journey driven by data
Databricks was a new technology for this healthcare product supplier that, when properly implemented, greatly improved the data science team’s access to data. Wavicle’s intervention allowed the company to understand that the Databricks feature store added value both through better data governance and quicker model development. This research, planning, and pilot execution effort was key for the customer’s data platform team as they set priorities in their greater Databricks roadmap.
The feature store MVP also allowed the company to test drive the Databricks feature store. The data platform team benefited by gaining an established pattern for moving further features from the silver layer to the feature store. The data science team also benefitted as the data from one of their most critical models became available in the feature store, so that they could evaluate its uses and plan for connectivity to their machine learning notebooks.
The feature store MVP was an important part of the company’s data journey in Databricks. The tool has been enabled, and more features will be added as the data science team’s priorities demand.
Related Posts


- Azure DevOps
- Databricks Lakehouse Platform
Hospitality and Gaming Enterprise Modernizes En...

- Databricks
- Databricks Mosaic AI
Financial Services Firm Transforms Contract Man...

- Google Cloud Platform (GCP)
- Terraform
Global QSR Ensures Uninterrupted Customer Exper...

- BigQuery
- Cloud Run
Global QSR Improves Sales with Micro-Segmentation

- Amazon S3
- AWS
Enterprise Databricks Cost Optimization for a G...

- Alteryx
- Amazon Redshift
Global QSR Strengthens GCP Migration with Indep...

- Amazon S3
- AWS
ARC and Wavicle Build Cloud-Based Solutions Tha...


- Airflow
- Bitbucket
MRO eCommerce Company Accelerates Assortment Ma...

- Databricks
- Databricks Unity Catalog
Retail Enterprise Advances eCommerce and Loyalt...

- Apache Spark
- AWS
Talend ETL Rebuilt on AWS, Cutting Costs and De...

- Azure
- Power BI
HVAC Manufacturer Uses EZForecast to Transform ...

- Amazon Quick Sight
- AWS
Structured Power BI to Amazon Quick Sight Migra...
- Microsoft Power BI
- Power BI
Financial Services Company Migrates from Tablea...

- Amazon Aurora
- Amazon S3
Global QSR Standardizes Shift Leadership Verifi...

- HubSpot
- Label Traxx
From “We Think” to “We Know”: How BGR Found The...

- Amazon S3
- AWS
Global QSR Saves $1 Million in Cloud Costs in 9...

- AWS
- AWS Inspector
Leading Auto Marketplace Eliminates 2,400+ Vuln...


- Azure DevOps
- C#
Global Packaging Material Manufacturer Moderniz...

- Amazon Quick Sight
Turbocharging Voice of Customer Analytics Using...

- Databricks
- EZForecast
Empowering Planners with Interactive Forecastin...

- Azure
- Databricks
Global Packaging Material Manufacturer Streamli...

- Databricks
- Databricks Lakehouse Platform
Global QSR Chain Strengthens Data Governance by...
- Google Cloud Platform (GCP)
- Tableau
Modernizing ESG Data for Resilience and Compliance

- Azure
- Databricks
Healthcare Company Optimizes Cloud Costs in Pre...

- Amazon Quick Sight
- AWS
Seamlessly Migrating 550+ Dashboards from Table...

- Amazon Quick Sight
- AWS
Seamlessly Migrating 550+ Dashboards from Table...

- Amazon Quick Sight
- AWS
Global Digital Platform Migrates from Tableau t...

- Microsoft Azure
- Power BI
Manufacturer Transforms Forecasting Process Wit...

- Databricks
- Databricks Unity Catalog
Ensemble Health Partners Modernizes Data Govern...
- Azure
- Microsoft
Standards Body Centralizes Supply Chain Data to...

- Microsoft
- Power BI
U.S. Air Force Leverages Wavicle’s EZConvertBI ...

- MicroStrategy
- SAP Business Objects
International Manufacturer Leverages Wavicle’s ...

- Machine Learning Studio
- Microsoft
Greenhouse Grower Improves Yield Predictions Th...

- Amazon Quick Sight
- AWS
Rail Technology Services Provider Upgrades Anal...

- Amazon Quick Sight
- Amazon S3
Global Automotive Supplier Modernizes Reporting...

- Azure
- Microsoft
Greenhouse Grower Modernizes Data and Insights ...

- Amazon Redshift
- BigQuery
Major Home Builder Leverages Snowflake to Catal...


- Salesforce Net Zero Cloud
- Talend
QSR Improves Sustainability Initiatives With Ac...


- Amazon Athena
- Amazon Quick Sight
International Coffee Chain Modernizes Business ...

- Amazon SageMaker
- AWS
Hotel Chain Enhances Customer Insights With Dev...

- Databricks
- Databricks Unity Catalog
How Pilot Company is Reducing Costs, Accelerati...

- Amazon S3
- AWS
Pilot Company Transforms Data Ecosystem to Unif...

- Power BI
- Snowflake
Merchants Fleet Fuels Growth With Modern Data A...

- Amazon Redshift
- Amazon S3
Medical Equipment Manufacturer Saves Millions o...

- Amazon Aurora
- Amazon Elastic Container Service (ECS)
Accelerating Store-Level Speed to Insight for P...

- Amazon Quick Sight
- AWS
Automotive Supplier Leverages Data Modernizatio...

- Amazon Redshift
- Tableau
QSR Maximizes Franchise Performance Using BI Vi...

- Azure Data factory
- Microsoft Azure
Manufacturer Unlocks Growth With Unified Custom...

- Azure
- Azure ML
Automotive Retailer Modernizes Data Management ...



- Azure DevOps
- Azure Event Hubs
Auto Retailer Uses Azure Cloud-Native Applicati...

- Amazon Athena
- Amazon Redshift
Accelerated Data Validation With Wavicle’s Data...

- AWS
- Snowflake
Major Insurer Transforms Operations With Modern...

- Amazon Connect
- Amazon DynamoDB
Retail/CPG Leader Accelerates Data Pipeline to ...

- Amazon Quick Sight
- Amazon Redshift
Vyaire Medical Gets Global Sales, Inventory, an...

- AWS
- AWS Aurora
Travel Center Operator Accelerates Access to Da...

- Amazon S3
- AWS
Travel Center Operator Migrates to Cloud Data W...


- .NET
- Amazon Redshift
New Ordering System Uses Machine Learning to Op...

- Amazon Redshift
- AWS
Global QSR Uses Micro-Segmentation to Improve C...

- .NET
- Amazon Redshift
Modernizing ESG Data for Resilience and Compliance


- Amazon Redshift
- AWS
For a Global Quick-Service Restaurant, Improvin...

- Amazon Redshift
- Amazon S3
Electronics Manufacturer Optimizes Global Logis...

- Amazon Redshift
- Amazon S3
Modernizing ESG Data for Resilience and Compliance

- AWS
- IBM DataStage
Global QSR Accelerates Migration from Legacy ET...

- Amazon Redshift
- Amazon S3
Integrated Procurement Analytics Platform Drive...

- Amazon Redshift
- Apache Spark
Cloud Migration Brings Agility and Innovation t...

- Amazon Redshift
- AWS
Intuitive POS Data Mart Drives Smarter Analyst ...

- Amazon Quick Sight
- Amazon Redshift
Post-Merger Data Consolidation Reduces Reportin...

- Amazon Redshift
- Tableau
Global QSR Orders Up Fast Data-Driven Solutions

- Amazon Redshift
- AWS