


- Azure DevOps
- Azure Event Hubs
Auto Retailer Uses Azure Cloud-Native Applications for Improved Customer Journey



This technology-forward auto retailer is focused on increasing customer engagement with a flexible and personalized experience that includes streamlined associate touchpoints. With a mature Azure environment in place, they were looking to transform their data, analytics, and machine learning processes by applying DevOps principles, including DataOps, MLOps, and ModelOps disciplines (XOps), to meet the needs of an increasingly sophisticated and demanding customer segment.
By coordinating cross-discipline teams with Agile processes and promoting shared responsibility, experimentation, and feedback loops with modernized processes and tooling, the auto retailer shifted to a resilient continuous delivery model to transform critical aspects of their business.
The challenge: Leveraging key moments in the customer journey
This retailer has a significant challenge engaging an increasingly sophisticated consumer audience making a big-ticket purchase. Consumers demand a retail experience that understands their latest actions, choices, and preferences. With increased customer demand and a constrained supply chain, the business needed more than ever to proactively identify and engage customers at various stages in their journey.
Together, these factors have created a challenge for the auto retailer’s data science and machine learning (DSML) department, which must manage, update, and add models to meet those expectations. Legacy data pipelines and relic DevOps processes often led to slow updates and were unable to serve modern use cases. Integrating new data sources and updating customer data in real time will allow the business to anticipate customers’ needs better.
This leading retailer wanted to implement a stalled customer model to identify and remove customer engagement barriers by nudging associates to reach out to customers at key moments and making it easier to identify customer friction points. Features would be based on customer actions, such as the latest web activity, and time passed since the customer’s last activity, which is more challenging to configure. These triggers would alert the appropriate business unit and support associate to help based on the recommended action.
Developing these features required coordination built into the data pipelines to provide the latest customer data to the data scientists to implement the model for the next best action. It also required building an alert for software engineers to create the framework to identify the stall, score the customer, and relay the score to the proper team.
Additional pain points
Teams within the department worked in an ad hoc fashion, following best practices within their area of expertise. However, when it came to productionizing key models, substantial effort went into reaching across silos to get partners up to speed to accomplish the implementation. This duplicated effort and created tech debt by prioritizing “getting value now” through single-use solutions that could not be generalized or shared for follow-up work.
There were a variety of pain points across the department that needed to be addressed:
- Software engineers (DevOps) struggled with incomplete version control systems, dashboards that lacked business intelligence, cumbersome model hand-off processes between engineers and data scientists, and the way applications were maintained as monolithic artifacts with many intertwined components.
- Data scientists (MLOps) struggled with inconsistent monitoring, manual model deployment, cumbersome feature exploration practices, disorganized code maintenance, and siloed model building.
- Data engineers (DataOps) struggled with a lack of information about what features were being explored and used, the need to negotiate data pipelines between on-prem tabular databases and cloud storage, and the way data pipelines existed in a bubble and were not associated with either DevOps or machine learning (ML code).
- Data scientists and data analysts (ModelOps) struggled with manual dashboard generation, heavy lifting to update dashboards for new or changed models, and the need to interpret dashboards for business reporting.
These challenges required a culture change to sustain the variety of machine learning (ML) professions. This was accomplished with Agile practices across application development and a modern tech stack that would scale with customer demand and be resilient to provide business continuity.
The solution: An Agile approach to modernization
The automotive retailer saw the possibilities Azure could offer to modernize their processes and applications and partnered with Wavicle to execute their vision. Wavicle started by applying DevOps principles to accelerate delivery, reduce time to value, and remove bottlenecks across the entire application. This DevOps mindset for data and analytics (XOps) included the disciplines of DataOps, ModelOps, and MLOps.
First, Wavicle drove the vision forward by creating objectives and key results (OKRs) to align all teams. Then, Wavicle’s consultants used Agile processes to align the tasks and level-set across machine learning professions and personas. ML professionals met to solidify OKRs, define scope, align definitions, and create high-level milestones. Individual teams then broke out for further refinement, creating stories and estimating complexity and unknowns. This encouraged a culture of shared responsibility, experimentation within bounds, and fast feedback.
The team determined that the best approach was to modernize and re-platform applications as they came up in the OKRs rather than migrate or re-host all existing applications. They chose this route for a few reasons:
- Leadership prioritized time-to-market for solutions over reducing existing footprints or gaining the immediate cost savings that migrating would have provided.
- Engineers and data scientists wanted to focus on implementing business logic and making those critical data leaps, so they went with platform-as-a-service (PaaS) resources where possible.
- The team was already cloud-ready technically and financially, as the organization already had a solid foothold in Azure.
This approach significantly increased the productivity and security of solutions since legacy capabilities did not need accommodation and only new capabilities were built. Consequently, development velocity increased since engineers needed to focus on a more limited, modern architecture.
How Wavicle applied DevOps principles
The highest-impact DevOps principles in this application development tooling modernization revolved around the following areas:
- Continuous integration and continuous deployment (CI/CD) was implemented for reliability and faster time to market. This included using GitHub as a code repository and mechanism for code reviews and Azure DevOps to kick off Function Apps for CI/CD.
- Managed services (especially serverless) tools were used for scalability and performance wherever possible. This included Cosmos DB as the primary target database because of its schema-on-read structure, ability to scale, and millisecond serving speed; Azure ML as the target for registered models, utilizing fully managed endpoint deployment; and Event Hubs for the publication/subscription model to capture and queue up model output for consumption.
- Microservice architecture was used for coordinated components. This included common repos in a hierarchical fashion for compartmentalization and reusability, cookie cutter repo as a common template for new applications, and agreement from teams on when a code set or functionality needed to be broken out into a separate microservice.
An example value stream map for customer flow state support:
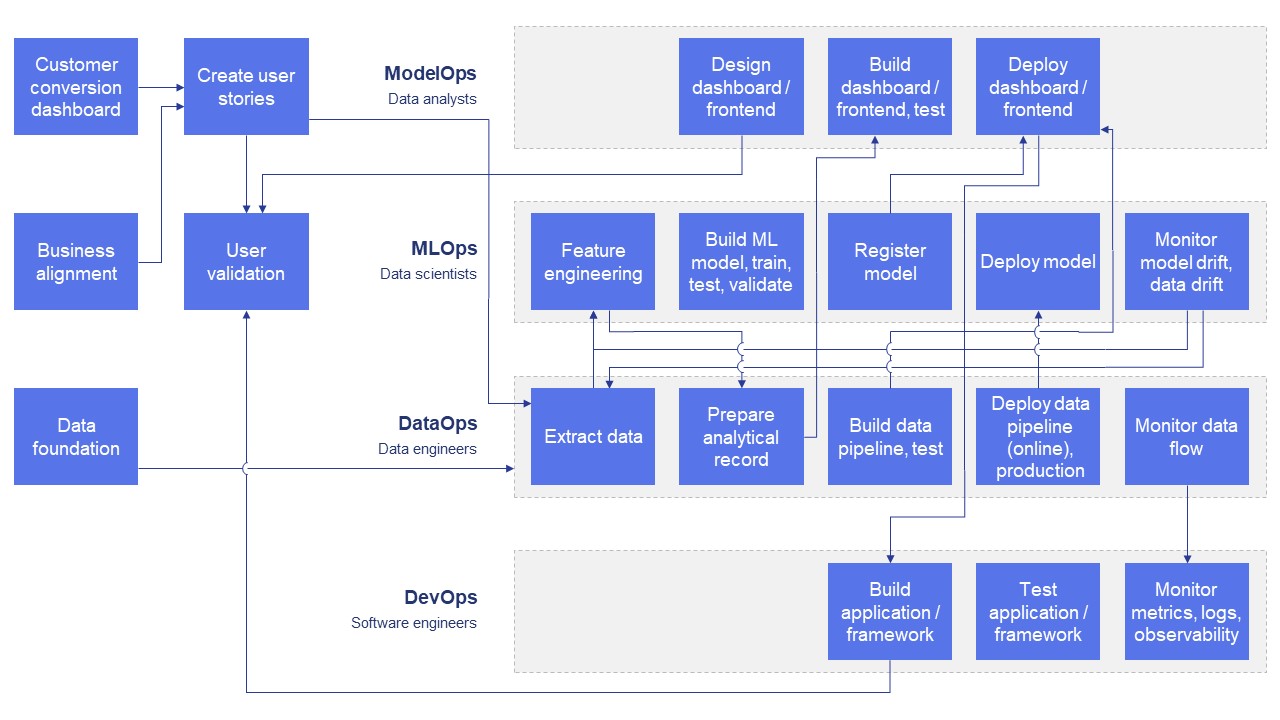
As the team began applying DevOps principles among the disciplines, clear advantages emerged. The CI/CD pattern for setting up projects rapidly increased the team’s ability to experiment with fast feedback loops. Many engineers had limited experience implementing a pub/sub model required for the information exchange in the stalled customer model. Even small code changes to Bicep templates for infrastructure could be written, tested in sandbox or dev environments, and immediately included for the rest of the team to build upon. This way, they could responsibly share the code via commits and pull requests (PRs) back to principal engineers to confirm they coded and solved problems using department norms and best practices.
The use of managed services rapidly transformed the team’s ability to attack new problems. There was a lot of trust from leadership that engineers would responsibly tag and control costs where possible. All engineers could create resource groups and resources, so anyone could be responsible for testing new deployment patterns or discovering better ways to tweak settings for increased performance and capabilities.
Following a microservice architecture approach allowed the team to be more agile and segregate functionality into smaller services instead of a single, monolithic deployment. This loosely coupled approach gave the various personas more autonomy to develop and deploy their components without waiting for or interrupting the work of other team members on a particular project. This separation paired nicely with CI/CD principles by quickly and easily testing the independent services impacted by any change and deploying them in isolation without breaking any other microservices.
Benefits of applying DevOps principles to analytics and ML projects
Each group received several benefits from the implementation:
- Software engineers (DevOps) benefitted from implementing GitHub as a collaboration focal point and deploying everything as Infrastructure as Code (IaC) using Bicep templates, which allowed them to work on and test resource instances before committing code and automatically deploy and test successful PRs using Function Apps.
- Data scientists (MLOps) benefitted from GitHub’s capacity to templatize and control versions for notebooks and segment workflows for more effective hand-offs, as well as from the ability to directly engage with the business to refine user stories and report findings to demonstrate model value.
- Data engineers (DataOps) benefited from new data pipelines hosted as source services and provider services, additional flexibility from managed services to tailor infrastructure resources to data sources and needs, and continuous work with data scientists to integrate new sources.
- Data scientists and data analysts (ModelOps) benefitted from the ability to capture model output in Event Hubs for scalability and the use of Azure Monitor to create dashboards directly in Azure Portal so stakeholders could access model monitoring capabilities.
See how the architecture works:
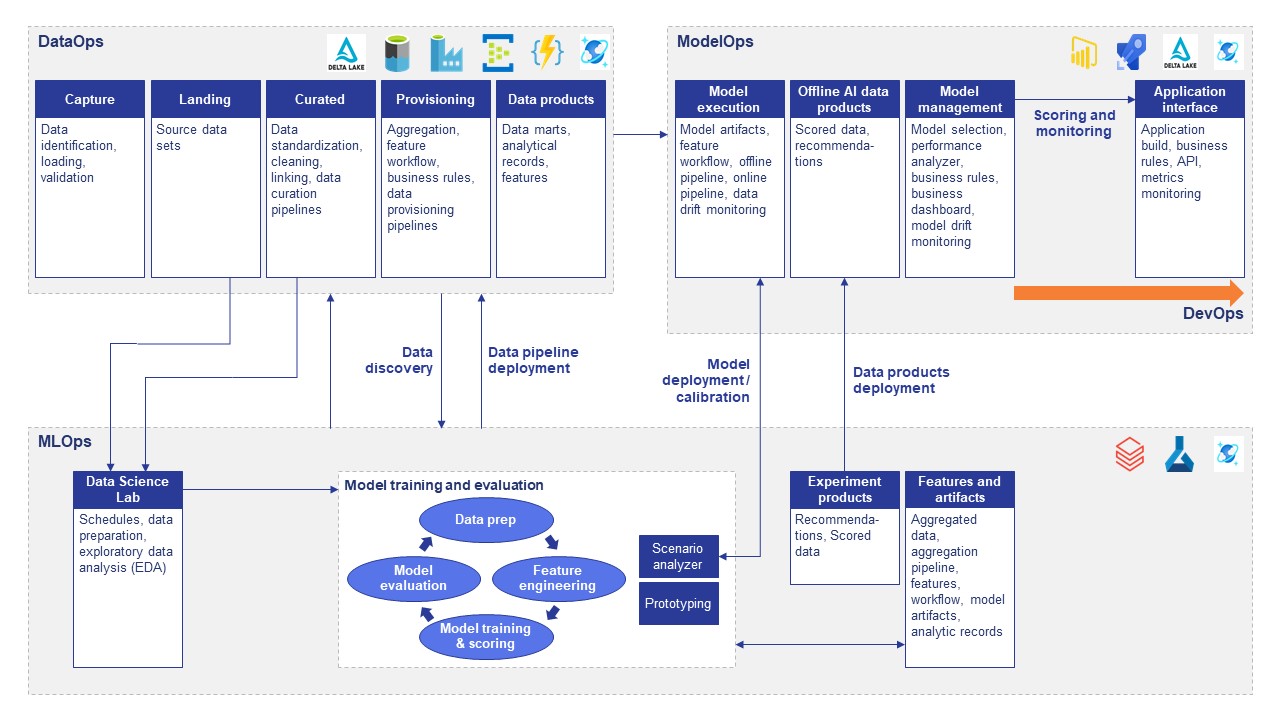
The outcome: An improved customer journey driven by data
This automotive retailer can now interact with customers on an unprecedented level.
Overall, associates are able to have higher quality touchpoints on a customer journey. Support associates receive prompts to proactively reach out to stalled customers with targeted actions and reasons the customers may have been experiencing friction.
Following this modernization effort, making changes and adding additional functionality are now significantly simpler, as there are no longer technical barriers. The company only has to agree on the business logic. This modernization also included removing some large, mundane bottlenecks, such as reducing hand-off time, increasing collaboration between development teams, and enabling faster data movement and dashboard development.
Broader advantages that would accelerate later projects included:
- Built an advanced, common microservices repository framework
- Delivered an increasingly automated value stream for each model
- Reduced model update time for data scientists
- Implemented more advanced capabilities that were crucial for business value
- Delivered better, more personalized experiences to customers
- Provided more relevant information to support associates
The focus on DevOps principles also helped the auto retailer by driving efficiencies throughout their teams. With the Agile process, team members can better estimate difficulty and unknowns. This also reduced fears about making updates, especially for more junior resources, and issues can now be addressed quickly using the entire market of managed services. Sandbox and automated testing allowed more assurance that changes, once tested and reviewed, would not cause any production downtime. Plus, continuous testing and continuous deployment meant code was immediately online and available to other developers for future work.
This project also accelerated onboarding time for the auto retailer’s new resources. New team members now have immediate access to the latest code (data pipelines, models, and frameworks) in GitHub and can be assigned issues. They can then be assigned bite-size microservices for improvement or fixing without having to learn the entire monolithic deployment. With managed services, the focus is on solving the business problem instead of learning the intricacies of a custom-built system.
Related Posts


- Databricks
- Databricks Mosaic AI
Financial Services Firm Transforms Contract Man...

- Google Cloud Platform (GCP)
- Terraform
Global QSR Ensures Uninterrupted Customer Exper...

- BigQuery
- Cloud Run
Global QSR Improves Sales with Micro-Segmentation

- Amazon S3
- AWS
Enterprise Databricks Cost Optimization for a G...

- Alteryx
- Amazon Redshift
Global QSR Strengthens GCP Migration with Indep...

- Amazon S3
- AWS
ARC and Wavicle Build Cloud-Based Solutions Tha...


- Airflow
- Bitbucket
MRO eCommerce Company Accelerates Assortment Ma...

- Databricks
- Databricks Unity Catalog
Retail Enterprise Advances eCommerce and Loyalt...

- Apache Spark
- AWS
Talend ETL Rebuilt on AWS, Cutting Costs and De...

- Azure
- Power BI
HVAC Manufacturer Uses EZForecast to Transform ...

- Amazon Quick Sight
- AWS
Structured Power BI to Amazon Quick Sight Migra...
- Microsoft Power BI
- Power BI
Financial Services Company Migrates from Tablea...

- Amazon Aurora
- Amazon S3
Global QSR Standardizes Shift Leadership Verifi...

- HubSpot
- Label Traxx
From “We Think” to “We Know”: How BGR Found The...

- Amazon S3
- AWS
Global QSR Saves $1 Million in Cloud Costs in 9...

- AWS
- AWS Inspector
Leading Auto Marketplace Eliminates 2,400+ Vuln...


- Azure DevOps
- C#
Global Packaging Material Manufacturer Moderniz...

- Amazon Quick Sight
Turbocharging Voice of Customer Analytics Using...

- Databricks
- EZForecast
Empowering Planners with Interactive Forecastin...

- Azure
- Databricks
Global Packaging Material Manufacturer Streamli...

- Databricks
- Databricks Lakehouse Platform
Global QSR Chain Strengthens Data Governance by...
- Google Cloud Platform (GCP)
- Tableau
Modernizing ESG Data for Resilience and Compliance

- Azure
- Databricks
Healthcare Company Optimizes Cloud Costs in Pre...

- Amazon Quick Sight
- AWS
Seamlessly Migrating 550+ Dashboards from Table...

- Amazon Quick Sight
- AWS
Seamlessly Migrating 550+ Dashboards from Table...

- Amazon Quick Sight
- AWS
Global Digital Platform Migrates from Tableau t...

- Microsoft Azure
- Power BI
Manufacturer Transforms Forecasting Process Wit...

- Databricks
- Databricks Unity Catalog
Ensemble Health Partners Modernizes Data Govern...
- Azure
- Microsoft
Standards Body Centralizes Supply Chain Data to...

- Microsoft
- Power BI
U.S. Air Force Leverages Wavicle’s EZConvertBI ...

- MicroStrategy
- SAP Business Objects
International Manufacturer Leverages Wavicle’s ...

- Machine Learning Studio
- Microsoft
Greenhouse Grower Improves Yield Predictions Th...

- Amazon Quick Sight
- AWS
Rail Technology Services Provider Upgrades Anal...

- Amazon Quick Sight
- Amazon S3
Global Automotive Supplier Modernizes Reporting...

- Azure
- Microsoft
Greenhouse Grower Modernizes Data and Insights ...

- Amazon Redshift
- BigQuery
Major Home Builder Leverages Snowflake to Catal...


- Salesforce Net Zero Cloud
- Talend
QSR Improves Sustainability Initiatives With Ac...


- Amazon Athena
- Amazon Quick Sight
International Coffee Chain Modernizes Business ...

- Amazon SageMaker
- AWS
Hotel Chain Enhances Customer Insights With Dev...

- Databricks
- Databricks Unity Catalog
How Pilot Company is Reducing Costs, Accelerati...

- Amazon S3
- AWS
Pilot Company Transforms Data Ecosystem to Unif...

- Amazon
- Amazon SageMaker
Healthcare Product Supplier Launches Feature St...

- Power BI
- Snowflake
Merchants Fleet Fuels Growth With Modern Data A...

- Amazon Redshift
- Amazon S3
Medical Equipment Manufacturer Saves Millions o...

- Amazon Aurora
- Amazon Elastic Container Service (ECS)
Accelerating Store-Level Speed to Insight for P...

- Amazon Quick Sight
- AWS
Automotive Supplier Leverages Data Modernizatio...

- Amazon Redshift
- Tableau
QSR Maximizes Franchise Performance Using BI Vi...

- Azure Data factory
- Microsoft Azure
Manufacturer Unlocks Growth With Unified Custom...

- Azure
- Azure ML
Automotive Retailer Modernizes Data Management ...



- Amazon Athena
- Amazon Redshift
Accelerated Data Validation With Wavicle’s Data...

- AWS
- Snowflake
Major Insurer Transforms Operations With Modern...

- Amazon Connect
- Amazon DynamoDB
Retail/CPG Leader Accelerates Data Pipeline to ...

- Amazon Quick Sight
- Amazon Redshift
Vyaire Medical Gets Global Sales, Inventory, an...

- AWS
- AWS Aurora
Travel Center Operator Accelerates Access to Da...

- Amazon S3
- AWS
Travel Center Operator Migrates to Cloud Data W...


- .NET
- Amazon Redshift
New Ordering System Uses Machine Learning to Op...

- Amazon Redshift
- AWS
Global QSR Uses Micro-Segmentation to Improve C...

- .NET
- Amazon Redshift
Modernizing ESG Data for Resilience and Compliance


- Amazon Redshift
- AWS
For a Global Quick-Service Restaurant, Improvin...

- Amazon Redshift
- Amazon S3
Electronics Manufacturer Optimizes Global Logis...

- Amazon Redshift
- Amazon S3
Modernizing ESG Data for Resilience and Compliance

- AWS
- IBM DataStage
Global QSR Accelerates Migration from Legacy ET...

- Amazon Redshift
- Amazon S3
Integrated Procurement Analytics Platform Drive...

- Amazon Redshift
- Apache Spark
Cloud Migration Brings Agility and Innovation t...

- Amazon Redshift
- AWS
Intuitive POS Data Mart Drives Smarter Analyst ...

- Amazon Quick Sight
- Amazon Redshift
Post-Merger Data Consolidation Reduces Reportin...

- Amazon Redshift
- Tableau
Global QSR Orders Up Fast Data-Driven Solutions

- Amazon Redshift
- AWS