
With the advent of big data technology, Apache Spark has gained much popularity in the world of distributed computing by offering a faster, easier to use, and in-memory framework as compared to the MapReduce framework. It can be used with any distributed storage such as HDFS, Apache Cassandra and MongoDB.
MongoDB is one of the most popular NoSQL databases. Its unique capabilities to store document-oriented data using the built-in sharding and replication features provide horizontal scalability and high availability.
By using Apache Spark as a data processing platform on top of a MongoDB database, one can leverage the following Spark API features:
The MongoDB connector for Spark is an open-source project written in Scala, to read and write data from MongoDB.
This feature holds good in rare cases since most of the work to optimize the data load in the workers is done automatically by the connector.
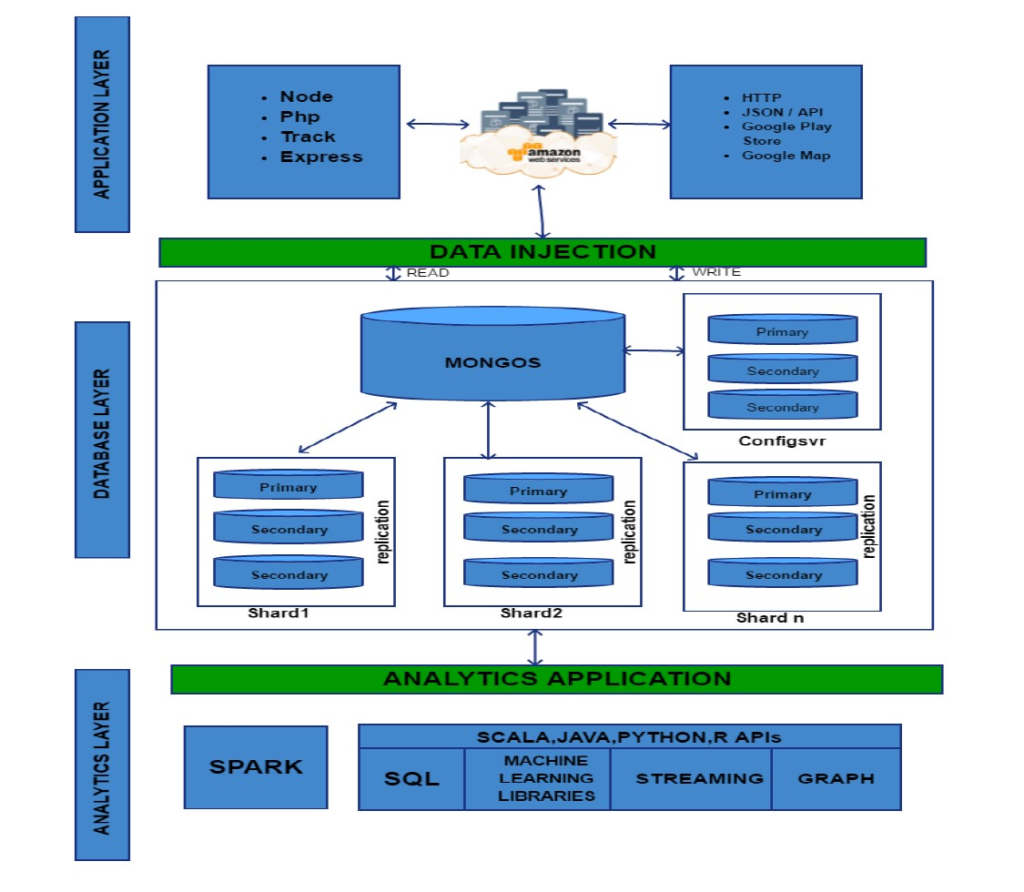
Different use cases can benefit from Spark built on top of a MongoDB database. They all take advantage of MongoDB’s built-in replication and sharding mechanisms to run Spark on the same large MongoDB cluster used by the business applications to store their data. Typically, applications read/write on the primary replica set while the Spark nodes read data from a secondary replica set.
Spark fuels analytics and it can be used to extract data from MongoDB, run complex queries and then write the data back to another MongoDB collection. This processing power of Spark eliminates the need of new data storage. If there is an already existing centralized storage such as a Data Lake built with HDFS for instance, Spark can extract and transform data from MongoDB before writing it to HDFS.
The advantage is that Spark can be used as a simple and effective ETL tool to move the data from MongoDB to the data lake. The ability to load the data on Spark nodes based on their MongoDB shard location is another optimization from MongoDB. The MongoDB connector’s utility methods simplify the interactions between Spark and MongoDB, thus making it a powerful combination to build sophisticated analytical applications.