


Deep Multi-Input Models Transfer Learning For Image and Word Tag Recognition
- Advanced Analytics
- Machine Learning & MLOps
 14 Jun 2021
14 Jun 2021- 15 min read


With the advancement of deep learning such as convolutional neural network (i.e., ConvNet) [1], computer vision becomes a hot scientific research topic again. One of the main goals of computer vision nowadays is to use machine learning (especially deep learning) to train computers to gain a human-level understanding of digital images, texts, or videos.
With its widespread use, ConvNet becomes the de facto model for image recognition. As described in [1], generally speaking, there are two approaches for using ConvNet for computer vision:
- Training a new ConvNet model from scratch
- Using transfer learning, that is, using a pre-trained ConvNet model
As shown in the following diagram, a ConvNet model consists of two parts: a convolutional base and a fully connected classifier.
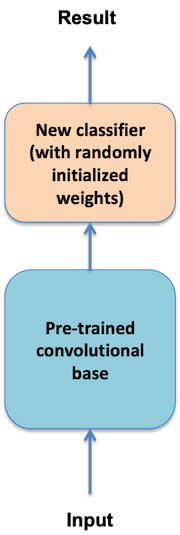
Figure 1: Typical scenario of ConvNet transfer learning.
The ConvNet transfer learning can be further subdivided into three methods:
- Method 1: Feature extraction without image argumentation [1]
This method uses a pre-trained convolutional base to convert new images into arrays such as Numpy arrays (they can be saved into files if necessary) first and then use those array representations of images in memory to train a separate new classification model with randomly initialized weights. - Method 2: Feature extraction with image argumentation [1]
This method builds a new model with the pre-trained convolutional base as the input layer, freezes the weights of the convolutional base, and finally adds a new output classifier with randomly initialized weights. - Method 3: Fine-tuning [1]
This method does not use the whole frozen pre-trained convolutional base. It allows unfreezing some of the top layers of a frozen pre-trained convolutional base so that those unfrozen top layers can be jointly trained with a new fully-connected classifier.
Method 2 is used in this article for multi-input model transfer learning.
The main idea behind transfer learning can be used to supervise ConvNet and other deep learning algorithms such as the unsupervised word embedding models for natural language processing (NLP)[4].
There are two popular pre-trained word embedding models: word2vec and GloVe [3]. Like the word2vec-keras model used in [4], these pre-trained word embedding models are usually combined with other supervised deep learning algorithms such as the recurrent neural network (RNN) LSTM for NLP such as text classification [4].
A ConvNet model or an NLP model (e.g., a combination of word embedding with LSTM) can be used separately to solve many interesting problems in computer vision and NLP. As to be shown in this article, these different types of models can also be combined in various ways [1] to form more powerful models to address more challenging problems such as insurance claim process automation that require not only the capability of image recognition but also natural language (e.g., texts) understanding.
This article uses an interesting but challenging dataset in Kaggle, Challenges in Representation Learning: Multi-modal Learning [2], to present a new multi-input transfer learning model that combines two input models with a fully connected classification layer for both image recognition and word tag recognition at the same time (see Figure 2).
The main idea behind the new multi-input model is to translate image and word tag recognition into a machine learning classification problem, that is, determining whether or not a given image matches a given set of word tags (0-No, 1-Yes).
1. Data preparation
After the Kaggle dataset of image files and word tag files [2] has been downloaded onto a local machine, the code below can be used to build and shuffle the lists of image file names and related word tag file names. There are 100,000 image files and 100,000 corresponding word tag files in the dataset for training purposes.
original_dataset_dir = './multi_task_learning/data/ESPGame100k'
base_dataset_dir = './multi_task_learning/data/ESPGame100k_small'
original_label_path = original_dataset_dir + '/labels'
original_label_files = [f for f in listdir(original_label_path) if isfile(join(original_label_path, f))]
original_image_path = original_dataset_dir + '/thumbnails'
original_image_files = [f for f in listdir(original_image_path) if isfile(join(original_image_path, f))]
original_image_files = np.array(original_image_files)
original_label_files = np.array(original_label_files)
dataset_size = original_label_files.shape[0]
perm = np.arange(dataset_size)
np.random.shuffle(perm)
original_image_files = original_image_files[perm]
original_label_files = original_label_files[perm]
To train the new multi-input model on a laptop within a reasonable amount of time (a few hours), I randomly selected 2,000 images and corresponding 2,000-word tag files for model training for this article:
if not os.path.isdir(base_dataset_dir):
os.mkdir(base_dataset_dir)
small_label_path = os.path.join(base_dataset_dir, 'labels')
small_image_path = os.path.join(base_dataset_dir, 'thumbnails')
if not os.path.isdir(small_label_path):
os.mkdir(small_label_path)
if not os.path.isdir(small_image_path):
os.mkdir(small_image_path)
for fname in original_label_files[:2000]:
src = os.path.join(original_label_path, fname)
dst = os.path.join(small_label_path, fname)
shutil.copyfile(src, dst)
for fname in original_label_files[:2000]:
img_fname = fname[:-5]
src = os.path.join(original_image_path, img_fname)
dst = os.path.join(small_image_path, img_fname)
shutil.copyfile(src, dst)
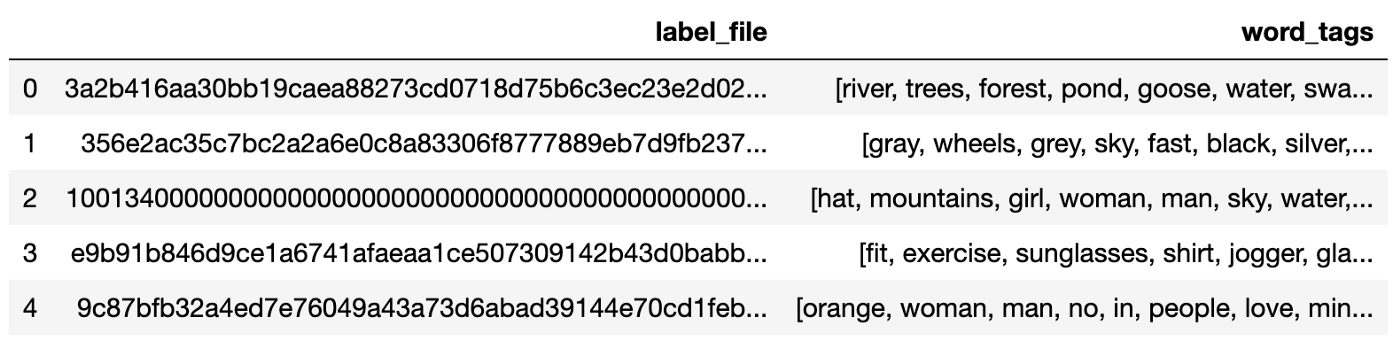
The code below is to load the 2,000 image tag file names and the corresponding 2,000-word tags into Pandas DataFrame:
label_map = {'label_file' : [], 'word_tags' : []}
for fname in listdir(small_label_path):
f = join(small_label_path, fname)
if isfile(f):
f = open(f)
label_map['label_file'].append(fname)
line = f.read().splitlines()
label_map['word_tags'].append(line)
label_df = pd.DataFrame(label_map)
label_df.head()
Similarly to [4], a textual data preprocessing procedure is included in the Jupyter notebook [5] to perform minimum data preprocessing such as removing stop words and numeric numbers in case it makes a significant difference:

As described in [4], the impact of textual data preprocessing is insignificant, and thus the raw word tags without preprocessing are used for model training in this article.
2. Architecture of multi-input models transfer learning
The diagram below shows that the new multi-input transfer learning model uses the pre-trained ConvNet model VGG16 for receiving and handling images and a new NLP model (a combination of the pre-trained word embedding model GloVe and Keras LSTM) for receiving and handling word tags. These two input models are merged first and then combined with a fully connected output classification model that uses both the image recognition model output and the NLP model output to determine whether or not an input pair of an image and a set of word tags is a match (0-No, 1-Yes).
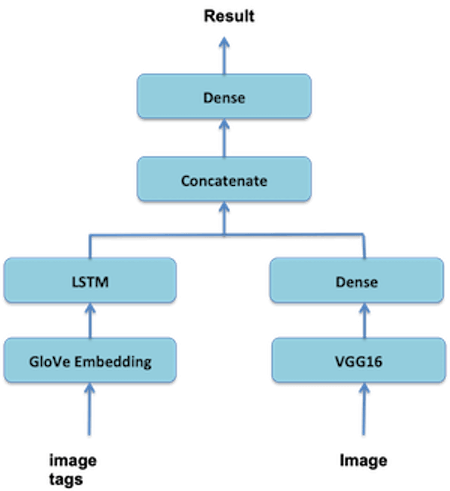
Figure 2: The architecture of the new deep learning model for multi-input models transfer learning.
3. Transfer learning for image recognition
As shown in Figure 2, the new multi-input transfer learning model uses the pre-trained ConvNet model VGG16 for image recognition. The VGG16 model has already been included in the Keras library. The following code from [1] is used to combine the VGG16 convolutional base with a new fully-connected classifier to form a new image recognition input model:
from keras.applications import VGG16
image_input = Input(shape=(150, 150, 3), name='image')
vgg16 = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))(image_input)
x = layers.Flatten()(vgg16)
x = layers.Dense(256, activation='relu')(x)
4. Transfer learning for text classification
As shown in Figure 2, the new multi-input transfer learning model uses the pre-trained word embedding model GloVe [3] for converting word tags into compact vectors. Once the GloVe dataset [3] has been downloaded to the local machine, the following code from [1] can be used to load the word embedding model into memory:
glove_dir = './multi_task_learning/data/'
embeddings_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'))
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
As it can be seen in Figure 2, the GloVe word embedding is combined with Keras LSTM to form a new NLP input model for predicting/recognizing word tags:
tag_input = Input(shape=(None,), dtype='int32', name='tag')
embedded_tag = layers.Embedding(max_words, embedding_dim)(tag_input)
encoded_tag = layers.LSTM(512)(embedded_tag)
5. Combining multi-input models with fully connected classifier
Once the new image recognition input model and the new NLP input model have been created, the following code can combine them with a new output classifier into one multi-input transfer learning model:
concatenated = layers.concatenate([x, encoded_tag], axis=-1)
output = layers.Dense(1, activation='sigmoid')(concatenated)model = Model([image_input, tag_input], output)
model.summary()
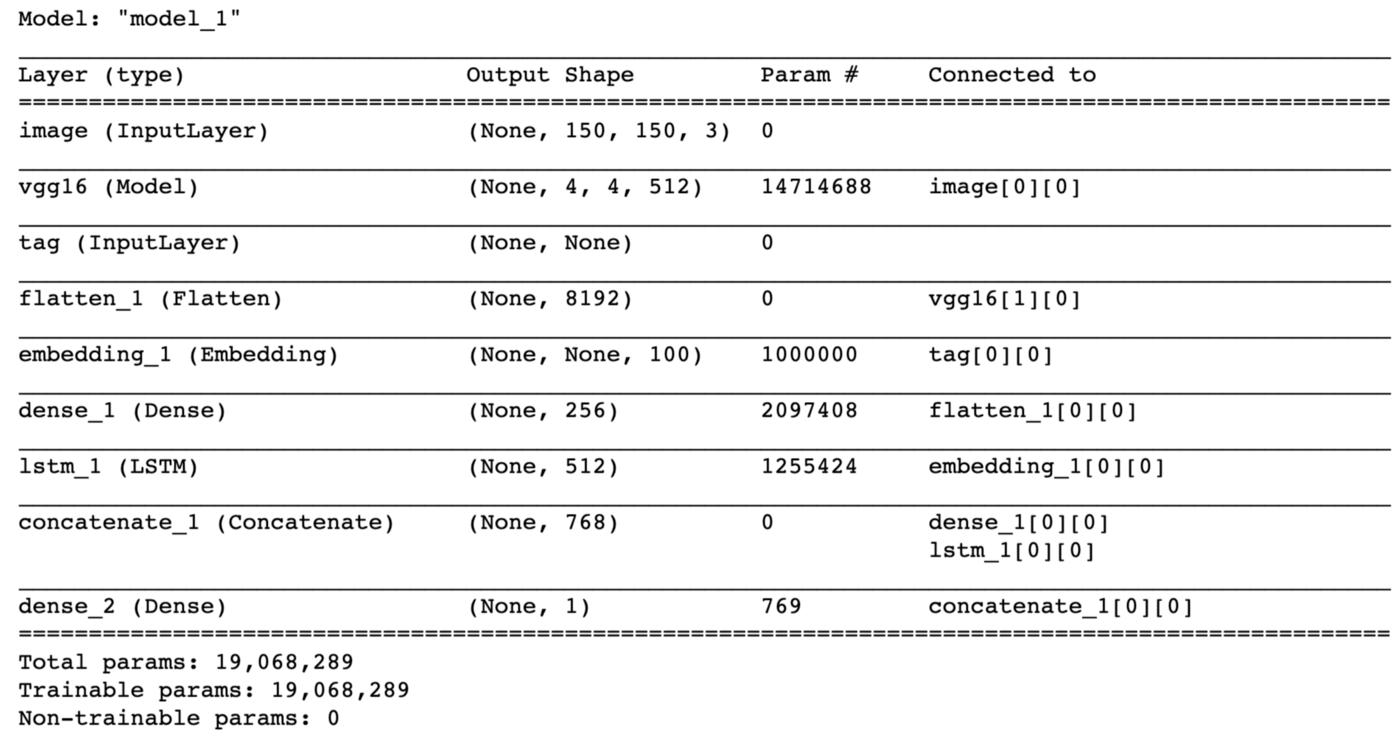
As described in [1], both the pre-trained VGG16 convolutional base and the GloVe word embedding layer must be frozen so that the pre-trained weights of those models will not be modified during the new multi-input model training:
# model.layers[1].trainable = False # freeze VGG16
model.layers[4].set_weights([embedding_matrix])
model.layers[4].trainable = False # freeze GloVe word embedding
However, regarding the VGG16 convolutional base, it is interesting to note that I tried both ways (frozen and not frozen) but did not see a significant difference in terms of model training time or model prediction results.
6. Multi-Input model training
The original Kaggle training dataset includes only the correct pairs of images and corresponding word tags. Each correct pair is labeled as 1 (match) in this article (also see the code below). To create a balanced dataset, the following code creates 2,000 incorrect pairs of images and word tags in addition to the existing 2,000 correct pairs of images and word tags. For simplicity, this is achieved by pairing each (say Image i) of the selected 2,000 images with the word tags of the following image file (i.e., word tags of Image i+1).
import cv2
dim = (150, 150)
X_image_train = []
X_tag_train = tag_data
y_train = []
for fname in listdir(small_image_path):
fpath = os.path.join(small_image_path, fname)
im = cv2.imread(fpath)
im_resized = cv2.resize(im, dim, interpolation = cv2.INTER_AREA)
X_image_train.append(im_resized)
y_train.append(1)
# add incorrect image and tag pairs
num_negative_samples = len(y_train)
for i in range(num_negative_samples):
image = X_image_train[i]
X_image_train.append(image)
j = (i + 1) % num_negative_samples # get a different tag
tag = X_tag_train[j]
X_tag_train = np.append(X_tag_train, tag)
y_train.append(0)
There are 4,000 pairs of images and word tags in total, 2,000 correct pairs, and 2,000 incorrect pairs.
Each of the image word tags needs to be encoded as an integer, and each list/sequence of word tags needs to be converted into a sequence of integer values before the word tags can be consumed by the word embedding model. This is achieved as follows by using and modifying the code in [1]:
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
maxlen = 100
training_samples = num_of_samples
tag_vocabulary_size = 10000
max_words = tag_vocabulary_size
num_of_samples = label_df.shape[0]
tokenizer = Tokenizer(num_words=max_words)
texts = []
for tag_list in label_df_clean['word_tags']:
texts.append(' '.join(tag_list))
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print('Found {} unique tokens'.format(len(word_index)))
tag_data = pad_sequences(sequences, maxlen=maxlen)
The resulting image and word tag training datasets are converted into Numpy arrays and shuffled for model training:
X_image_train = np.array(X_image_train)
X_tag_train = np.array(X_tag_train)
y_train = np.array(y_train)
perm = np.arange(y_train.shape[0])
np.random.shuffle(perm)
X_image_train = X_image_train[perm]
X_tag_train = X_tag_train[perm]
y_train = y_train[perm]
The new multi-input model is compiled and trained as follows with only 30 epochs and 4,000 balanced pairs of images and word tags:
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
model.fit([X_image_train, X_tag_train], y_train, epochs=30, batch_size=64)

7. Model prediction
As shown below, the private testing dataset in [2] includes 500 images, and each image is associated with two sets of word tags:

Given an image in the testing dataset, the new multi-input transfer learning model needs to predict which of the given two sets of word tags matches the image.
The following code is to load the testing images into memory:
dim = (150, 150)
X_image_test = []
for fname in listdir(test_image_dir):
fpath = os.path.join(test_image_dir, fname)
im = cv2.imread(fpath)
im_resized = cv2.resize(im, dim, interpolation = cv2.INTER_AREA)
X_image_test.append(im_resized)
The testing word tags are converted into a sequence of encoded integer values as follows:
tokenizer_test = Tokenizer(num_words=max_words)
texts_1 = []
texts_2 = []
texts_all = []
for tag_list in test_image_label_df['word_tags_1']:
texts_1.append(' '.join(tag_list))
for tag_list in test_image_label_df['word_tags_2']:
texts_2.append(' '.join(tag_list))
texts_all.extend(texts_1)
texts_all.extend(texts_2)
tokenizer_test.fit_on_texts(texts_all)
sequences_1 = tokenizer_test.texts_to_sequences(texts_1)
sequences_2 = tokenizer_test.texts_to_sequences(texts_2)
word_index_test = tokenizer_test.word_index
print('Found {} unique tokens in test'.format(len(word_index_test)))
tag_data_test_1 = pad_sequences(sequences_1, maxlen=maxlen)
tag_data_test_2 = pad_sequences(sequences_2, maxlen=maxlen)
The resulting Python arrays of images and word tags are then converted into Numpy arrays and fit into the trained model for prediction:
X_image_test = np.array(X_image_test)
X_tag_test_1 = np.array(tag_data_test_1)
X_tag_test_2 = np.array(tag_data_test_2)
y_predict_1 = loaded_model.predict([X_image_test, X_tag_test_1])
y_predict_2 = loaded_model.predict([X_image_test, X_tag_test_2])
The following table shows the first 20 prediction results:
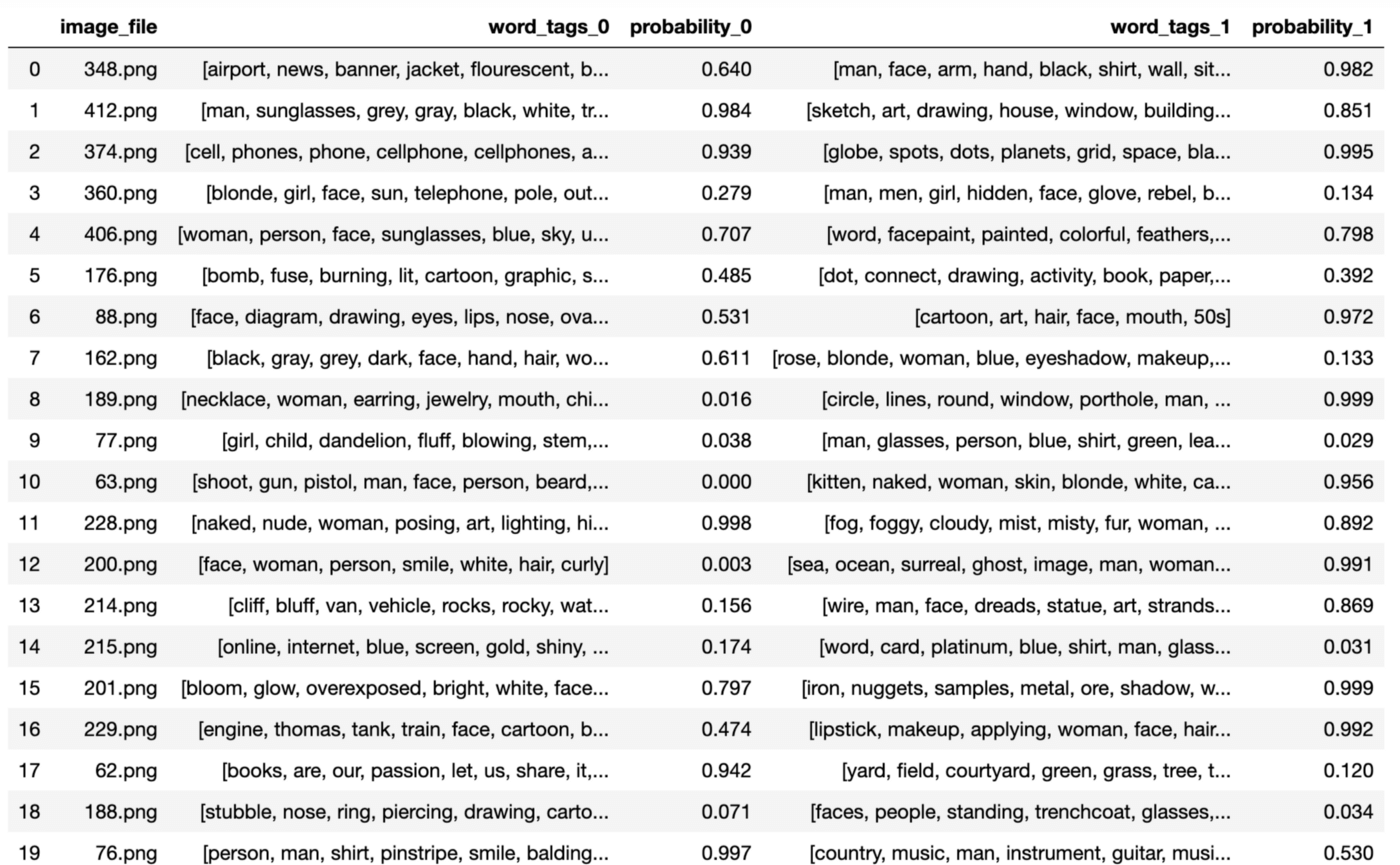
The following image is Image 201.png in the testing dataset:

The two associated sets of word tags are as follows:
word-tag-set-0: ['bloom', 'glow', 'overexposed', 'bright', 'white', 'face', 'woman', 'blonde']
word-tag-set-1: ['iron', 'nuggets', 'samples', 'metal', 'ore', 'shadow', 'white', 'grey', 'gray', 'rust', 'shiny']
The model predicts:
word-tag-set-0: probability of 0.797
word-tag-set-1: probability of 0.999
The answer with the higher probability of 0.999 is:
[‘iron’, ‘nuggets’, ‘samples’, ‘metal’, ‘ore’, ‘shadow’, ‘white’, ‘grey’, ‘gray’, ‘rust’, ‘shiny’]
As another positive example, the following is Image 76.png in the testing dataset:
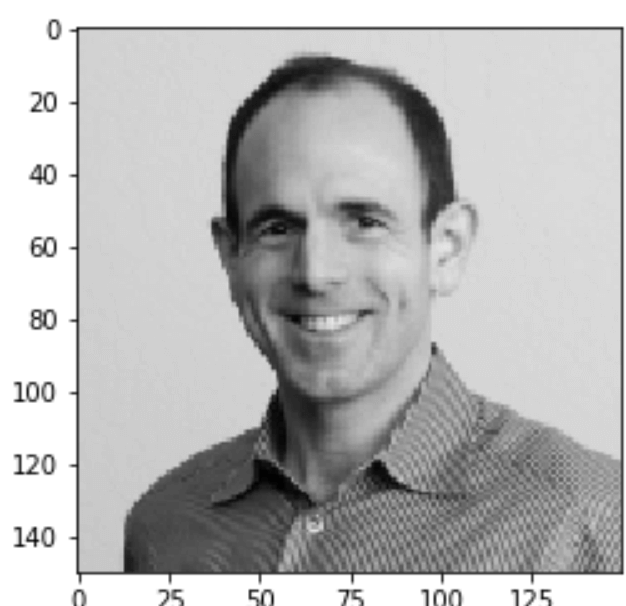
The following are the associated two sets of word tags:
word-tag-set-0: ['person', 'man', 'shirt', 'pinstripe', 'smile', 'balding', 'grey', 'gray']
word-tag-set-1: ['country', 'music', 'man', 'instrument', 'guitar', 'musician', 'person', 'playing', 'watch', 'striped', 'shirt', 'red', 'glasses']
The model predicts:
word-tag-set-0: probability of 0.997
word-tag-set-1: probability of 0.530
The answer with the higher probability of 0.997 is:
[‘person’, ‘man’, ‘shirt’, ‘pinstripe’, ‘smile’, ‘balding’, ‘grey’, ‘gray’]
As a false positive example, the following is Image 189.png in the testing dataset:
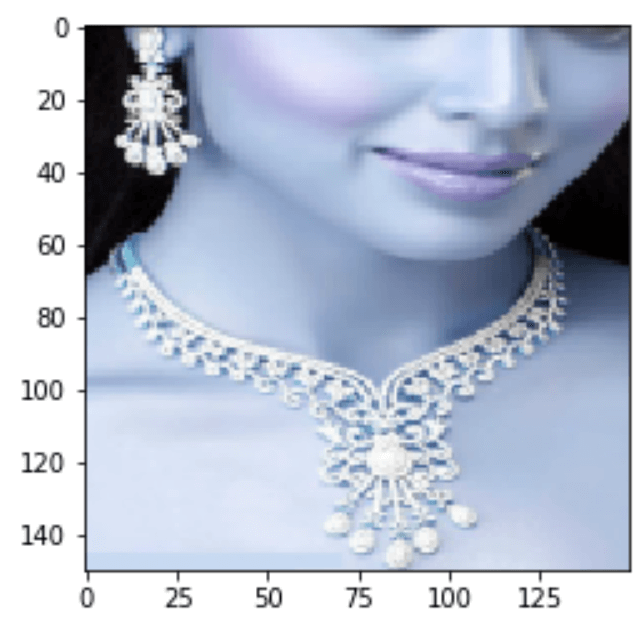
The following are the associated two sets of word tags:
word-tag-set-0: ['necklace', 'woman', 'earring', 'jewelry', 'mouth', 'chin', 'closeup']
word-tag-set-1: ['circle', 'lines', 'round', 'window', 'porthole', 'man', 'face', 'beard', 'person', 'dark', 'shadow']
The model predicts:
word-tag-set-0: probability of 0.016
word-tag-set-1: probability of 0.999
The false-positive answer with the higher probability of 0.999 is:
[‘circle’, ‘lines’, ‘round’, ‘window’, ‘porthole’, ‘man’, ‘face’, ‘beard’, ‘person’, ‘dark’, ‘shadow’]
The testing results above show that even though the new multi-input transfer learning model is trained with only 4,000 pairs of images and word tags and 30 epochs, the model obtained quite reasonable results in terms of accuracy.
However, the model also generated quite some false positives due to model overfitting.
Summary
This article presented a new multi-input deep transfer learning model that combines two pre-trained input models (VGG16 and GloVe & LSTM) with a new fully-connected classification layer for recognizing images and word tags simultaneously.
The key point of the new multi-input deep learning method is to translate the problem of image and word tag recognition into a classification problem, that is, determining whether or not a given image matches a given set of word tags (0-No, 1-Yes).
The challenging public dataset in Kaggle, Challenges in Representation Learning: Multi-modal Learning [2], was used to train and evaluate the new model.
The model prediction results demonstrated that the new model performed reasonably well with limited model training (only 30 epochs and 4,000 pairs of images and word tags) for demonstration purposes. However, with no surprise, the model also generated quite some false positives due to model overfitting. This issue can be addressed by training the model with more epochs and more pairs of images and word tags.
A randomly chosen 2,000 training images were not good enough representative of a total of 100,000 available training images. Therefore, the model performance should be improved significantly by increasing training images from 2,000 to a larger size like 10,000.
A Jupyter notebook with all of the source code is available on GitHub [5].
References
[1] F. Chollet, Deep Learning with Python, Manning Publications Co., 2018
[2] Challenges in Representation Learning: Multi-modal Learning
[3] J. Pennington, R. Socher, C.D. Manning, GloVe: Global Vectors for Word Representation
[4] Y. Zhang, Deep Learning for Natural Language Processing Using word2vec-keras
[5] Y. Zhang, Jupyter notebook in Github
WIT Leader
Data Team
Builds secure, governed data platforms that power analytics and feed AI models with clean, real-time, and high-quality data.
View all my PostsRelated Posts


















- Blog
- Automated BI Migration
- Conversational Analytics
Automated BI Migration: Moving Tableau and Powe...
-
24 Apr 2026
-
10 min read

- Blog
- Automated ETL Migration
- AWS Glue
ETL Migration Cost Optimization: Legacy ETL to ...
-
24 Apr 2026
-
10 min read


- Blog
- Azure
- Databricks
Enabling Near Real-Time Operational Decision-Ma...
-
24 Feb 2026
-
5 min read
















- Blog
- Advanced Analytics
- Healthcare
Computer Vision for Health: Living Longer
-
07 Jul 2025
-
16 min read


- Blog
- Amazon Quicksight
- BI Reporting & Visualizations
5 Major Benefits of Amazon Quick Suite That you...
-
28 May 2025
-
3 min read



- Blog
- Amazon Quicksight
- BI Reporting & Visualizations
Tips and Tricks to Get the Most Out of Amazon Q...
-
07 May 2025
-
4 min read

- Blog
- Data Governance
- Healthcare
Rethinking Healthcare Data Governance: From Sil...
-
05 May 2025
-
3 min read

- Blog
- Data Management
- Healthcare
Building the Future of Healthcare Through Flawl...
-
02 May 2025
-
4 min read

- Blog
- Environmental Social & Governance (ESG)
Leveraging AI to Optimize Energy Consumption of...
-
30 Apr 2025
-
18 min read

- Blog
- Advanced Analytics
- Predictive Modeling
Predicting the Unpredictable: Leveraging AI to ...
-
11 Apr 2025
-
3 min read

- Blog
- Demand Forecasting
- Retail
The AI Storefront: How Retail and CPG Leaders C...
-
28 Mar 2025
-
2 min read

- Blog
- Advanced Analytics
When and Where GenAI Actually Makes Sense in Kn...
-
28 Mar 2025
-
16 min read


- Blog
- Advanced Analytics
- Retail
Navigating Ethical Issues of AI in Retail
-
12 Mar 2025
-
4 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
How Generative AI is Transforming Retail Custom...
-
12 Mar 2025
-
5 min read


- Blog
- Data Governance
Back to Basics: Essentials for Product Developm...
-
20 Feb 2025
-
23 min read


- Blog
- Advanced Analytics
- Generative AI & LLM
How Text Analytics and Generative AI Are Unlock...
-
09 Jan 2025
-
5 min read

- Blog
- BI Reporting & Visualizations
- Business Intelligence & Insights
Transforming BI Reporting and Visualization Wit...
-
06 Jan 2025
-
5 min read

- Blog
- Cloud Infrastructure Modernization
- Platform Management
Mastering Cloud Cost Optimization for a More Ef...
-
03 Jan 2025
-
5 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
How Generative AI is Transforming the Retail Ex...
-
20 Dec 2024
-
21 min read

- Blog
- Advanced Analytics
Preparing your Business for an AI-Driven Future
-
19 Dec 2024
-
10 min read

- Blog
- Advanced Analytics
What it Means to be Human in the Age of AI
-
12 Dec 2024
-
18 min read

- Blog
- Business Intelligence & Insights
- Reporting Modernization
How EZConvertBI Simplifies Your Looker Migration
-
12 Dec 2024
-
4 min read

- Blog
- Advanced Analytics
- Business Intelligence & Insights
Transforming Business Intelligence with Looker
-
12 Dec 2024
-
6 min read

- Blog
- Advanced Analytics
- Data Governance
Key Challenges in AI Adoption for Businesses
-
11 Dec 2024
-
13 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
What AI Disruption Means for Businesses
-
05 Dec 2024
-
15 min read

- Blog
- Advanced Analytics
- Business Intelligence & Insights
Optimizing Your Cloud Data Platform with Google...
-
04 Dec 2024
-
7 min read

- Blog
- Advanced Analytics
- Amazon Quicksight
From Shopfloor to Boardroom: Get Your Data to T...
-
21 Nov 2024
-
5 min read

- Blog
- BI Reporting & Visualizations
- Build & Migrations
Let Your Data Speak to You – Unlocking Organiza...
-
12 Nov 2024
-
5 min read

- Blog
- Advanced Analytics
- Business Analytics
The Joy of Decision-Making and Why It Matters
-
12 Nov 2024
-
5 min read

- Blog
- Data Management
- Strategy & Assessments
Understanding Data Products
-
11 Nov 2024
-
4 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
Crafting User-Focused Solutions and Building an...
-
06 Nov 2024
-
12 min read

- Blog
- Architecture & Engineering
- Cloud Infrastructure Modernization
How Data Mesh is Shaping the Future of Data Man...
-
05 Nov 2024
-
8 min read

- Blog
- Business Intelligence & Insights
- Reporting Modernization
Streamline your Power BI Migration with EZConve...
-
22 Oct 2024
-
4 min read

- Blog
- Advanced Analytics
Maximizing Business Transformation Through AI a...
-
15 Oct 2024
-
18 min read

- Blog
- Advanced Analytics
- BI Reporting & Visualizations
How Gen AI and Microsoft Copilot are Reshaping ...
-
03 Oct 2024
-
5 min read

- Blog
- Advanced Analytics
- Build & Migrations
Transforming Data Capabilities by Moving Beyond...
-
25 Sep 2024
-
5 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
How to Build a Restaurant Performance Measureme...
-
24 Sep 2024
-
6 min read

- Blog
- Advanced Analytics
- Business Analytics
Leveraging Data Science and AI to Drive Innovat...
-
16 Sep 2024
-
16 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
The Role of Mature Data and AI in Accurate Gene...
-
26 Aug 2024
-
14 min read

- Blog
- Advanced Analytics
- Business Analytics
Listening to the Voice of the Customer: A Key t...
-
21 Aug 2024
-
6 min read

- Blog
- Azure
- BI Reporting & Visualizations
Moving from Tableau to Power BI: Why Companies ...
-
20 Aug 2024
-
6 min read

- Blog
- Advanced Analytics
How AI Impacts the Ways We Develop and Grow Dat...
-
14 Aug 2024
-
18 min read

- Blog
- Advanced Analytics
- Demand Forecasting
How to Use Demand Forecasting to Improve Busine...
-
12 Aug 2024
-
6 min read

- Blog
- Business Intelligence & Insights
- Cloud Infrastructure Modernization
Building a Data Platform on Snowflake
-
01 Aug 2024
-
5 min read

- Blog
- Advanced Analytics
- Demand Forecasting
Why Your Demand Forecasting Model Doesn’t Work ...
-
30 Jul 2024
-
7 min read

- Blog
- Advanced Analytics
- Data Governance
Expert Insights on Demonstrating the Value of D...
-
22 Jul 2024
-
9 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
How to Effectively Harness Gen AI for Your Busi...
-
18 Jul 2024
-
5 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
Navigating the AI Hype Cycle by Setting Realist...
-
11 Jul 2024
-
15 min read

- Blog
- Advanced Analytics
- Data Management
Leveraging AI Technology in Healthcare
-
10 Jul 2024
-
17 min read

- Blog
- Advanced Analytics
- Data Governance
Expert Insights on Leveraging Data Quality and ...
-
01 Jul 2024
-
8 min read

- Blog
- Data Governance
- Privacy Governance & Compliance
Choosing the Right Data Governance Approach for...
-
24 Jun 2024
-
5 min read

- Blog
- Data Governance
- Privacy Governance & Compliance
Expert Insights on Leveraging Data Governance f...
-
11 Jun 2024
-
12 min read

- Blog
- Data Governance
- Data Management
The Role of Existing Data Stewards in Driving G...
-
10 Jun 2024
-
3 min read

- Blog
- Data Governance
- Data Management
Optimizing Data Governance Programs Beyond Chec...
-
03 Jun 2024
-
4 min read

- Blog
- Data Governance
- Privacy Governance & Compliance
Measuring Data Governance Progress With Metrics...
-
29 May 2024
-
4 min read

- Blog
- Data Governance
- Data Management
Decoding Data Governance: Going Beyond its Name
-
22 May 2024
-
5 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
How Your Data Governance Strategy Supports Data...
-
15 May 2024
-
4 min read

- Blog
- Data Governance
- Privacy Governance & Compliance
The Need for Data Governance in a Changing World
-
13 May 2024
-
4 min read

- Blog
- Manufacturing
How Smart Manufacturing and Digital Twins Are H...
-
06 May 2024
-
6 min read

- Blog
- Advanced Analytics
- Data Management
Crafting a Data Strategy to Support AI in Healt...
-
30 Apr 2024
-
13 min read

- Blog
- Data Management
- Data Privacy & Regulatory Compliance
How to Achieve Compliance Excellence in Healthc...
-
24 Apr 2024
-
5 min read


- Blog
- Environmental Social & Governance (ESG)
- Manufacturing
Modernizing Supply Chains for Resilience and Su...
-
17 Apr 2024
-
8 min read

- Blog
- Advanced Analytics
- Business Analytics
Getting the Absolute Best Data Science Talent t...
-
16 Apr 2024
-
14 min read

- Blog
- Architecture & Engineering
- Data Management
How to Design a Modern Data Architecture
-
10 Apr 2024
-
5 min read

- Blog
- Advanced Analytics
- Predictive Modeling
How to Re-imagine Customer Experience With Pred...
-
10 Apr 2024
-
4 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
Expert Insights on Transformative AI Strategies...
-
10 Apr 2024
-
13 min read

- Blog
- Data Management
- Strategy & Assessments
Why Your Organization Needs a Data Strategy
-
01 Apr 2024
-
4 min read

- Blog
- Data Management
- Strategy & Assessments
Getting Started With Data Strategy: The AI-Led ...
-
28 Mar 2024
-
3 min read

- Blog
- Cloud Infrastructure Modernization
- Cloud Security & Monitoring
The Role of AI and ML in Cloud Security Monitoring
-
21 Mar 2024
-
4 min read

- Blog
- Data Management
- Strategy & Assessments
Getting Started With Data Strategy: The Acceler...
-
20 Mar 2024
-
4 min read

- Blog
- Advanced Analytics
The Role of the Chief AI Officer (CAIO)
-
15 Mar 2024
-
13 min read

- Blog
- Data Management
- Strategy & Assessments
Getting Started With Data Strategy: The Traditi...
-
13 Mar 2024
-
4 min read

- Blog
- Healthcare
- Strategy & Assessments
How Building a Strong Data Strategy Boosts Heal...
-
12 Mar 2024
-
7 min read

- Blog
- Data Management
- Strategy & Assessments
The Do’s and Don’ts of Data Strategy
-
06 Mar 2024
-
6 min read

- Blog
- Advanced Analytics
- Manufacturing
The Role of Advanced Analytics and AI in Reduci...
-
04 Mar 2024
-
5 min read

- Blog
- Advanced Analytics
- Data Management
Reducing Barriers to Complex Data Science Entry...
-
15 Feb 2024
-
14 min read


- Blog
- Amazon Quicksight
- AWS
Mastering the Art of Visual Storytelling: Wavic...
-
29 Jan 2024
-
1 min read

- Blog
- Amazon Quicksight
- AWS
Getting to Know the Tableau-to-Amazon Quick Sui...
-
29 Jan 2024
-
3 min read

- Blog
- Manufacturing
Manufacturing Metrics That Elevate Performance ...
-
24 Jan 2024
-
8 min read

- Blog
- Restaurant
Mastering the Increasingly Complex QSR Landscape
-
18 Jan 2024
-
3 min read

- Blog
- Advanced Analytics
- Manufacturing
Manufacturing in 2024: Key Data and Analytics T...
-
12 Dec 2023
-
8 min read

- Blog
- Advanced Analytics
- Business Analytics
Data-Driven Dining: Three Essential Data, Analy...
-
20 Nov 2023
-
7 min read

- Blog
- Healthcare
2024 Healthcare Trends: Reimagining the Industr...
-
14 Nov 2023
-
6 min read

- Blog
- Advanced Analytics
- Business Analytics
Demystifying Data and Analytics
-
24 Oct 2023
-
12 min read

- Blog
- Healthcare
Exploring Data and Analytics in Healthcare: A Q...
-
12 Oct 2023
-
7 min read


- Blog
- Advanced Analytics
- Predictive Modeling
Revolutionizing Your Customer Experience Measur...
-
04 Oct 2023
-
10 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
How Integrating Reservation and POS Data Can Pr...
-
27 Sep 2023
-
4 min read

- Blog
- Advanced Analytics
- Business Intelligence & Insights
Next-Generation CDOs: A Conversation About the ...
-
25 Sep 2023
-
12 min read

- Blog
- Data Management
How Effective Data Management Helps to Realize ...
-
22 Sep 2023
-
6 min read

- Blog
- Business Intelligence & Insights
Why Data Analytics Projects Fail and How to Ove...
-
22 Sep 2023
-
5 min read

- Blog
- Advanced Analytics
- Machine Learning & MLOps
How to Build Resilient Business Strategies Usin...
-
22 Aug 2023
-
6 min read

- Blog
- Business Analytics
- Manufacturing
3 Ways Data Analytics Can Transform Your Supply...
-
01 Aug 2023
-
4 min read

- Blog
- Business Analytics
- Manufacturing
How is Data Analytics Transforming Production?
-
26 Jul 2023
-
5 min read

- Blog
- Advanced Analytics
- Predictive Modeling
5 Blockers to Effective Artificial Intelligence...
-
24 Jul 2023
-
6 min read

- Blog
- Data Governance
- Data Management
Instilling Data Quality Into Your Data Manageme...
-
20 Jul 2023
-
7 min read

- Blog
- Advanced Analytics
- Business Analytics
3 Ways Engineers Can Drive Business Value with ...
-
18 Jul 2023
-
4 min read

- Blog
- Advanced Analytics
- Predictive Modeling
Calculating ROI for Advanced Analytics Initiatives
-
15 Jul 2023
-
6 min read

- Blog
- Data Management
- Strategy & Assessments
How Business Leaders Leverage Data as a Critica...
-
15 Jun 2023
-
7 min read

- Blog
- Amazon Quicksight
- BI Reporting & Visualizations
Clear and Actionable: Wavicle’s Winning Dashboard
-
09 May 2023
-
2 min read

- Blog
- Cloud Infrastructure Modernization
- Platform Management
The Importance of Effective Cloud Platform Mana...
-
07 May 2023
-
4 min read

- Blog
- Data Management
How Businesses Benefit from Modern Data Managem...
-
02 May 2023
-
7 min read

- Blog
- Architecture & Engineering
- Data Management
Data Architecture 101: Trends and Terms to Know
-
25 Apr 2023
-
6 min read

- Blog
- Restaurant
Building a Contact-Free Smart System
-
20 Apr 2023
-
2 min read


- Blog
- Build & Migrations
- Data Management
Which Data Storage Solution is Right for Your O...
-
04 Apr 2023
-
6 min read

- Blog
- Manufacturing
What’s Next in Manufacturing? A Q&A With T...
-
02 Mar 2023
-
4 min read


- Blog
- Data Governance
Governing Your Data: How to Start Designing a G...
-
14 Feb 2023
-
3 min read

- Blog
- Data Governance
Data Governance Roles: Who Should Govern Your D...
-
07 Feb 2023
-
4 min read

- Blog
- Financial Services
Financial Services Executive Outlook: The Benef...
-
02 Feb 2023
-
3 min read

- Blog
- Financial Services
Financial Services Executive Outlook: The Path ...
-
26 Jan 2023
-
4 min read

- Blog
- Data Governance
The Path to Data Governance: What Data Will Be ...
-
24 Jan 2023
-
3 min read

- Blog
- ActiveInsights
- Advanced Analytics
The Future of Voice of Customer: 5 Trends to Watch
-
18 Jan 2023
-
8 min read

- Blog
- Financial Services
Financial Services Executive Outlook: Capitaliz...
-
12 Jan 2023
-
4 min read

- Blog
- Data Governance
What is a Customer? How Simple Questions Get Co...
-
05 Jan 2023
-
6 min read

-
29 Nov 2022
-
7 min read


- Blog
- Data Governance
- Data Privacy & Regulatory Compliance
Why a Good Governance, Privacy, and Compliance ...
-
08 Nov 2022
-
7 min read


- Blog
- Data Governance
Data Governance for Business Leaders: 3 Concept...
-
25 Oct 2022
-
5 min read



- Blog
- Financial Services
Financial Services Executive Outlook: The Impac...
-
29 Sep 2022
-
2 min read


- Blog
- Financial Services
Financial Services Executive Outlook: The Reali...
-
22 Sep 2022
-
3 min read







- Blog
- Augment
- AWS
ETL Modernization: Reduce Migration Timelines a...
-
02 Mar 2022
-
4 min read

- Blog
- Advanced Analytics
- Machine Learning & MLOps
Five Steps To Operationalizing Advanced Analyti...
-
24 Nov 2021
-
5 min read

- Blog
- Augment
- Data Privacy & Regulatory Compliance
A New Way to Quickly and Easily Discover PII Da...
-
19 Oct 2021
-
2 min read

- Blog
- Architecture & Engineering
- Augment
6 Reasons You Need an Augmented Data Quality So...
-
16 Sep 2021
-
5 min read

- Blog
- ActiveInsights
- Business Analytics
Ditch the Survey and Really Get to Know Your Cu...
-
15 Jul 2021
-
8 min read

- Blog
- Architecture & Engineering
- Business Analytics
Five Reasons Why Boutique Consulting Firms Are ...
-
21 Jun 2021
-
6 min read

- Blog
- Advanced Analytics
- Machine Learning & MLOps
Deep Learning For Natural Language Processing o...
-
08 Jun 2021
-
9 min read

- Blog
- ActiveInsights
- Customer 360
5 Ways to Successfully Win Travelers’ Loy...
-
25 May 2021
-
6 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
Want to Meet Consumer Expectations? Demand Fore...
-
25 May 2021
-
9 min read

- Blog
- Advanced Analytics
- Customer 360
These 3 Top Retail Analytics Trends are Revolut...
-
25 May 2021
-
7 min read

- Blog
- Demand Forecasting
Demand Forecasting Is Always Wrong: Three Ways ...
-
27 Apr 2021
-
5 min read

- Blog
- Architecture & Engineering
- Business Analytics
8 CDOs Share Key Insights on How to Build a Suc...
-
23 Apr 2021
-
6 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
Here’s Why 2021 is Actually the First “Year of ...
-
07 Apr 2021
-
10 min read

- Blog
- Advanced Analytics
- Business Analytics
Five Critical Elements For Successful Customer ...
-
17 Feb 2021
-
5 min read

- Blog
- Architecture & Engineering
- Business Analytics
Everything You Need to Know About Data & A...
-
15 Jan 2021
-
5 min read

- Blog
- Business Intelligence & Insights
- Data Management
What Happens When Insurers Turn to Data Analytics?
-
04 Jan 2021
-
4 min read

- Blog
- Architecture & Engineering
- Data Management
What Happens When ERP Systems Talk? The Results...
-
04 Jan 2021
-
5 min read

- Blog
- Data Management
- Data Privacy & Regulatory Compliance
Compliance Data Management: the Case For Automa...
-
02 Dec 2020
-
5 min read

- Blog
- Architecture & Engineering
- Data Management
Compliance Data Management: Data Preparation Sa...
-
02 Dec 2020
-
7 min read

- Blog
- Business Analytics
- Customer 360
Your Customers Like You, They Really, Really Li...
-
25 Aug 2020
-
9 min read

- Blog
- Predictive Modeling
- Restaurant
Why Micro-Segmentation Matters in a Post-COVID ...
-
10 Aug 2020
-
6 min read

- Blog
- Architecture & Engineering
- Data Management
Data Architecture From Right to Left: Start Wit...
-
18 May 2020
-
6 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
Using Big Data to Better Predict Your Recovery:...
-
11 May 2020
-
8 min read



- Blog
- Cloud Infrastructure Modernization
- Data Management
How to Get Faster, More Reliable Analytics from...
-
04 Dec 2019
-
7 min read

- Blog
- ActiveInsights
- Architecture & Engineering
Take Ownership of the Relationship with Your Di...
-
04 Dec 2019
-
4 min read

- Blog
- ActiveDeliver
- Business Intelligence & Insights
Food Delivery: Who Owns the Customer?
-
05 Nov 2019
-
5 min read



- Blog
- Business Analytics
- Business Intelligence & Insights
Quick Service Restaurants are Ravenous for Big ...
-
03 Apr 2019
-
4 min read

- Blog
- Architecture & Engineering
- Data Management
CDO Summit Key Takeaways
-
02 Apr 2019
-
7 min read

- Blog
- Advanced Analytics
- BI Reporting & Visualizations
2019 Business Intelligence Trends
-
16 Oct 2018
-
3 min read






