
As the regulatory environment for financial services has grown more complex and rigorous, organizations are seeking ways to reduce the time and cost of compliance reporting. Their sights are set on automation within their data management processes.
In our previous blog post, we explored the growing cost of compliance reporting and suggested that automation of complex data preparation tasks, such as data ingestion and data quality, can dramatically reduce the compliance workload.
These processes are heavily reliant on manual coding and data validation, which drive up the need for skilled resources and add weeks or months to compliance timelines. By adopting automation in these areas, financial institutions will benefit not only from reduced time and cost but also from improved trustworthiness of their compliance data.
First, let’s look at the process of data ingestion, which involves obtaining data from a variety of source systems and importing it into a data warehouse or data lake to be used or analyzed for various purposes – in this case, compliance reporting.
This is the first step in the process of achieving trusted data for your compliance program, so it should not be underestimated, particularly when it involves connecting to multiple data sources.
This step includes building or customizing source system APIs to capture the data needed for compliance reports. But the job doesn’t stop there. These connections must be updated continuously as data structures or system configurations change – and they do change constantly. Then, as you add new data sources, or as compliance reporting requirements change, you have to build new connections or reconfigure the ingestion rules to capture new data.
At the same time, it’s critical to manage the ordering and prioritization of data as it moves through the system to ensure the accuracy of the data. All of this requires significant coding and ongoing maintenance, which are potentially contributing to reporting inaccuracies and delays.
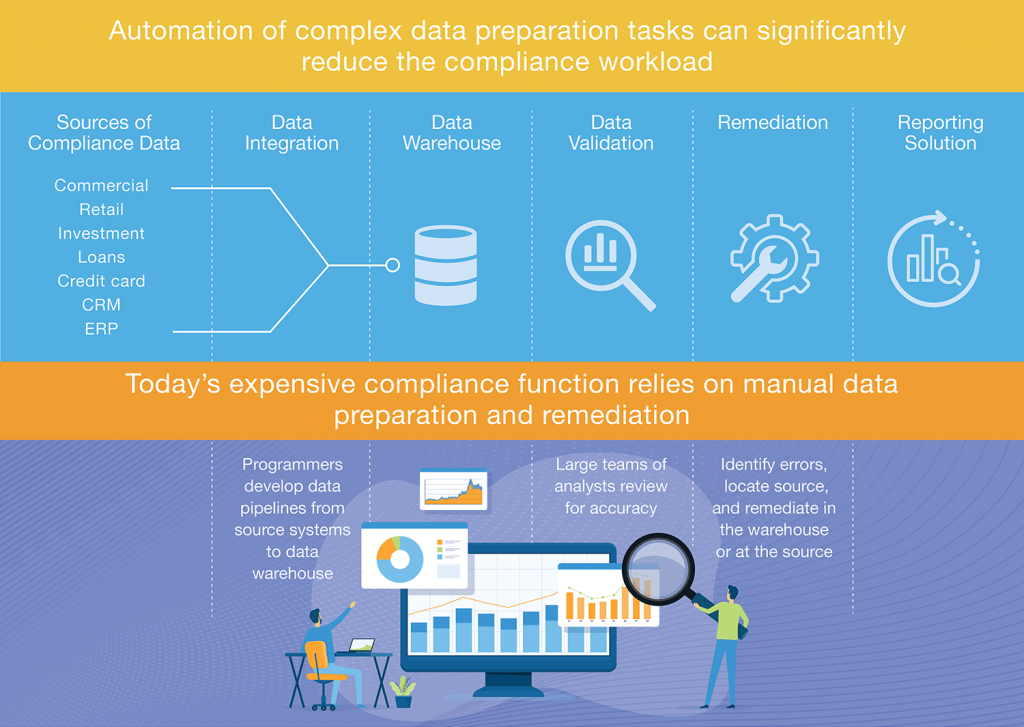
By automating much of this coding work, you can accelerate the time for compliance reporting by weeks, or even months, and improve the productivity of your team.
Depending on your organization’s capabilities, you may consider developing a homegrown solution, however, a variety of available tools can get you there faster. At Wavicle, we have built our Data Ingestion Framework, not only to reduce the time and cost of the data integration solutions we build for our clients but also so they can automate the ongoing management of data ingestion after our work has ended.
While these solutions should work for any use case, if you’re evaluating them specifically for compliance purposes, you should look for a solution that offers:
By automating your data ingestion process using these principles, you can shave weeks or months off your data integration timeline.
Next, let’s look at data quality. It’s not rare for data that gets loaded into a data warehouse or data lake to be inaccurate, duplicate, or incomplete, either because of how it was created or how it is being stored.
It’s no surprise, then, that data quality issues drive up the demand for resources to review compliance outputs, validate results, and track down the source of erroneous data. Left unchecked, poor data quality will lead to inaccuracies in compliance reports, which could result in significant financial penalties.
Over the years, some institutions have built homegrown solutions to detect data quality issues, but they often provide incomplete quality checks and do not scale with growing compliance needs. They can be difficult to modify to incorporate new data and requirements.
When you’re dealing with dozens of data sources and hundreds or thousands of database tables, you need a data quality solution that can quickly find missing, incomplete, or otherwise suspicious data, and show you exactly where that data is – without manually combing through tables and columns to find and remediate errors.
We’ve built a data quality application that we use for client data warehouse and data lake projects to accelerate the identification and remediation of data quality issues.
We wanted our solution to be fast and easy to use for technical and non-technical users alike, and identified several requirements that we recommend you also look for in a data quality solution:
With our data quality application, we have been able to reduce time spent on data quality for our clients by as much as 70%.
This underscores the value of automating data preparation tasks to reduce the cost and time of compliance reporting. By simplifying data management and organization, you dramatically improve your ability to stay on top of the constantly changing regulatory environment.
To see how Wavicle can bring a fresh focus to compliance reporting, visit our website.