


ETL Migration Cost Optimization: Legacy ETL to AWS Glue PySpark
- Automated ETL Migration
- AWS Glue
- ETL Modernization
 24 Apr 2026
24 Apr 2026- 10 min read



Cloud adoption continues to accelerate, yet many enterprises still run core ETL workloads on legacy platforms like Informatica PowerCenter, Talend Data Integration, IBM DataStage, and SQL Server Integration Services. Industry analysis shows that over 60% of data integration deployments remain on-premises
At the same time, organizations migrating to cloud-native processing frameworks report significant cost improvements. Serverless platforms such as AWS Glue running Apache PySpark workloads can reduce ETL processing costs dramatically, with some reports citing up to 80% savings in certain workloads
However, migrating hundreds of tightly coupled legacy ETL pipelines is rarely straightforward. This guide explores the cost drivers behind ETL modernization and how automation tools like EZConvertETL can help accelerate migration to modern data platforms.
Organizations focused on reducing ETL costs are increasingly exploring Talend to AWS Glue migration as a scalable approach to modernize data pipelines.
TL;DR
- Many enterprises still run ETL pipelines on tools like Informatica PowerCenter, Talend Data Integration, IBM DataStage, and SQL Server Integration Services.
- As data volumes grow, these environments become expensive to maintain due to licensing, infrastructure, and operational overhead.
- ETL modernization to Apache PySpark running on AWS Glue provide a serverless, scalable alternative.
- The biggest challenge in modernization is migrating large numbers of existing ETL jobs.
- Automation tools like EZConvertETL help accelerate this process by converting legacy ETL pipelines into PySpark workflows.
What Is ETL Migration? Definition, Scope, and Cost Drivers
ETL migration is the process of moving existing data pipelines from legacy ETL platforms to modern data processing frameworks or cloud-native services.
At a high level, an ETL migration typically includes three layers of work:
- Pipeline conversion – Translating transformation logic, mappings, and workflows from proprietary ETL formats into PySpark or other modern frameworks.
- Infrastructure modernization – Moving ETL execution from dedicated servers or clusters to cloud-based or serverless compute environments.
- Validation and optimization – Ensuring migrated pipelines produce identical results while tuning them for performance, scalability, and cost efficiency.
Because most enterprises operate hundreds or thousands of pipelines, the real complexity of ETL migration is rarely the code itself, it is understanding dependencies, preserving business logic, and executing the transition without disrupting production data flows.
Why Legacy ETL Migration Has Become a Cost Imperative
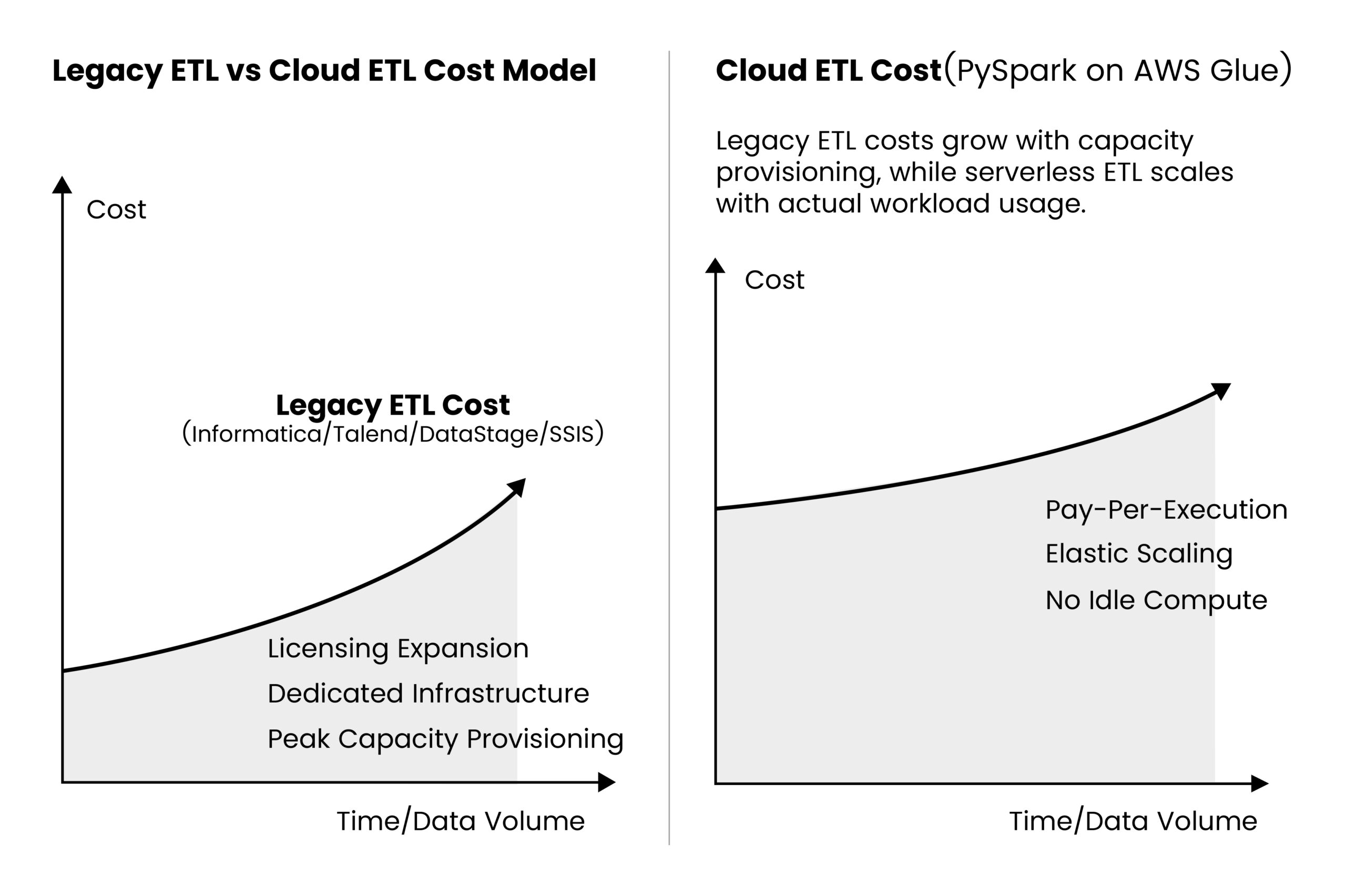
For many organizations, the push toward ETL migration is no longer driven only by modernization goals, it’s driven by cost.
In the past, data pipelines typically ran predictable nightly batches on infrastructure owned and managed by the enterprise. ETL tools were optimized for that environment: graphical workflow design, tightly controlled execution environments, and infrastructure sized for peak workloads.
Today, data platforms operate very differently. Data volumes grow continuously, analytics workloads are unpredictable, and pipelines must scale quickly to support real-time insights and machine learning workloads. In this environment, the economics of legacy ETL begin to break down.
Organizations often find themselves paying for:
- Fixed software licenses that scale with cores or environments
- Dedicated infrastructure sized for peak batch workloads
- Ongoing platform maintenance, upgrades, and operational support
For many data engineering leaders, legacy ETL modernization is increasingly about cost optimization as much as technical modernization.
This shift is why more teams are evaluating cloud-native processing frameworks like Apache Spark running on services such as AWS Glue, architectures designed to scale compute and cost together.
Comparing Legacy ETL Platforms vs PySpark on AWS Glue
Once organizations begin evaluating ETL migration cost, the difference between legacy ETL platforms and cloud-native processing frameworks becomes clearer. Traditional tools were built around fixed infrastructure and licensing models. By contrast, modern architectures using Apache PySpark on AWS Glue follow a consumption-based approach where compute scales dynamically with each job.
The difference isn’t just technical; it fundamentally changes how ETL costs behave as data workloads grow.
Enterprise ETL Cost Model Comparison
| Cost Factor | Informatica | Talend | DataStage | SSIS | AWS Glue + PySpark |
|---|---|---|---|---|---|
| License Cost | High | Medium | High | Medium | None |
| Infrastructure Cost | High | Medium | High | Medium | Low |
| Scaling Flexibility | Low | Low | Low | Medium | High |
| Idle Infrastructure Cost | High | Medium | High | Medium | Low |
| Operational Overhead | High | Medium | High | Medium | Low |
| Development Model | GUI | GUI + Code | GUI | SQL | GUI+Code (PySpark) |
| Scalability | Licence Upgrades | Pay Per Execution | |||
Why Legacy ETL Migration Is Harder Than It Looks
Tools like Informatica PowerCenter, Talend Data Integration, IBM InfoSphere DataStage, and SQL Server Integration Services often rely on complex visual workflows. While these graphical pipelines are easy to design initially, they hide the underlying transformation logic, dependencies, and execution sequences.
During migration, those hidden layers start to surface.
A single ETL workflow may depend on multiple upstream jobs, shared mappings, stored procedures, and scheduling rules. Recreating all that logic in PySpark can require manual interpretation of each transformation step, making migrations slow and error prone.
That’s why many ETL modernization projects stall. The challenge isn’t just rewriting pipelines; it’s untangling years of accumulated data engineering logic before the migration can even begin.
The Hidden Cost Drivers in Legacy ETL Environments
The cost of legacy ETL platforms isn’t limited to licenses or infrastructure. In many organizations, the bigger expense comes from the operational complexity that accumulates around long-running ETL environments built on legacy ETL
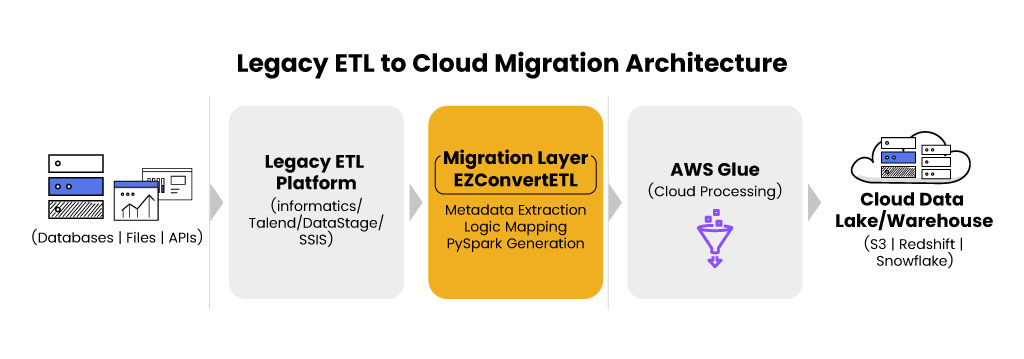
Over time, pipelines expand to support new data sources, additional transformations, and more reporting workloads. As this happens, ETL systems gradually require dedicated infrastructure, platform administration, and ongoing maintenance to keep jobs running reliably.
Several other factors that typically drive long-term ETL costs upward:
- Platform administration for upgrades, monitoring, and troubleshooting
- Maintenance of legacy pipelines that few engineers fully understand
- Operational risk when changes affect multiple dependent jobs
In contrast, modern data processing frameworks such as Apache PySpark running on AWS Glue reduce several of these overhead layers by shifting ETL execution to serverless infrastructure. Instead of maintaining dedicated ETL environments, teams focus primarily on pipeline logic and data processing.
Understanding these hidden cost drivers is often what pushes organizations to seriously evaluate ETL migration strategies.
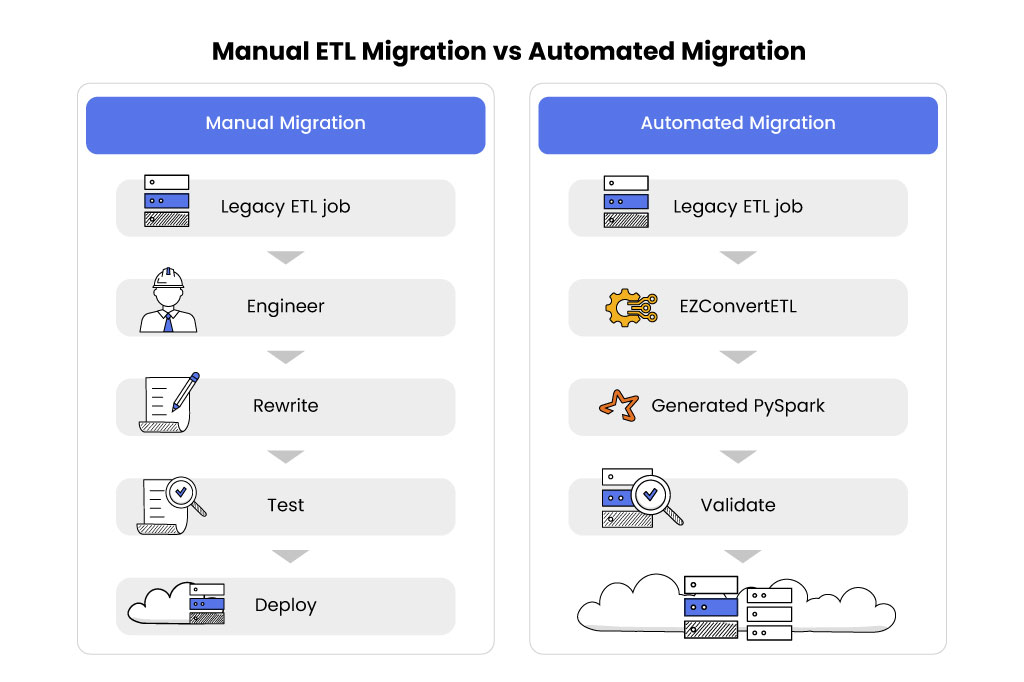
Manual ETL Migration: Why It Becomes a Multi-Year Project
When organizations begin moving from legacy ETL tools to modern frameworks like Apache PySpark on AWS Glue, the most common approach is manual migration. Data engineers review each pipeline built in legacy platforms and rewrite the logic in PySpark.
Each ETL job typically contains multiple transformations, joins, aggregations, filters, lookups, and data quality rules. Because legacy platforms rely heavily on graphical workflows, engineers must interpret the visual logic and translate it into code before rebuilding it in Spark. Migrating them sequentially for hundreds of pipelines at an enterprise level creates long timelines, while parallel migration increases coordination complexity.
As a result, manual ETL modernization projects frequently stretch across multiple quarters or even years, delaying the cost and scalability benefits organizations expect from moving to serverless data processing platforms.
Why Automated ETL Migration Is Gaining Adoption
As organizations confront the scale of manual migration, many begin exploring automation. Instead of rewriting every pipeline by hand, migration frameworks attempt to convert legacy ETL workflows into modern architectures. In practice, automated Talend to PySpark migration enables faster conversion while reducing manual effort and delivery risk.
For large ETL estates, this approach can significantly accelerate migration timelines. Instead of engineers interpreting every graphical workflow, automation can extract mappings, transformations, and data flows directly from the source platform and convert them into structured code.
Automation doesn’t eliminate engineering work entirely. However, it can remove much of the repetitive translation effort that slows down manual migrations. As a result, automated migration tools are becoming an increasingly important part of large-scale ETL modernization initiatives.
A Practical Approach to Migrating ETL Workloads to AWS Glue
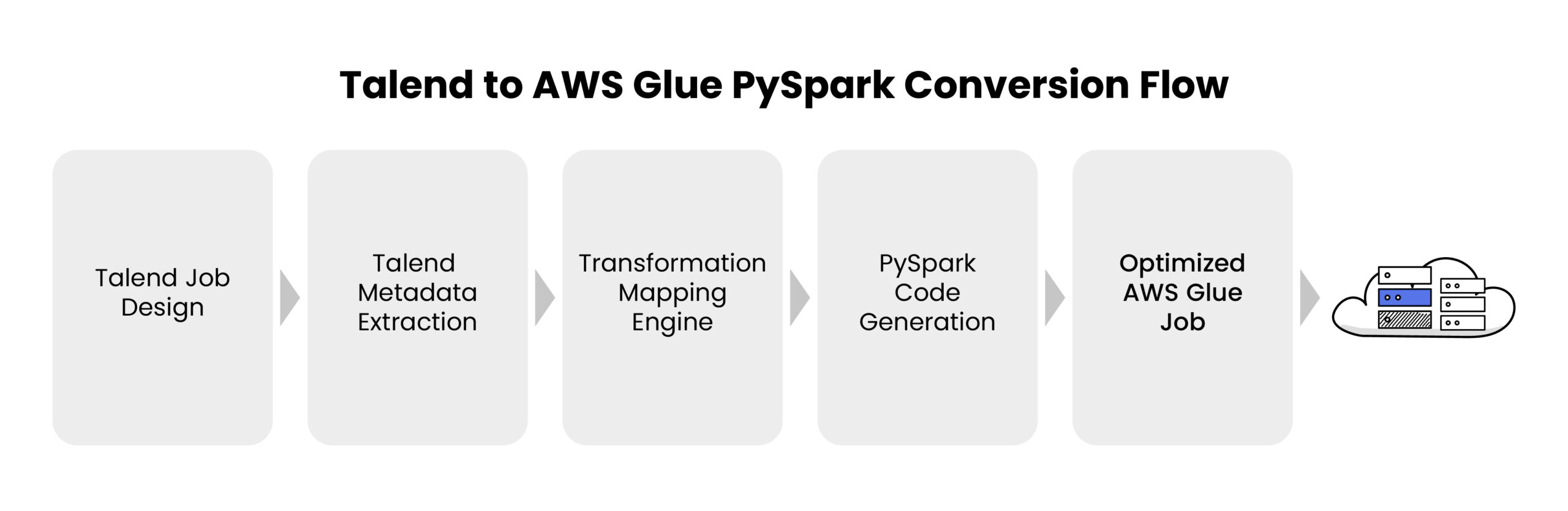
Successful ETL migration rarely happens in a single step. Most organizations moving from legacy ETL platforms to modern frameworks such as Apache Spark on AWS Glue follow a phased strategy.
A structured approach helps reduce migration risk while ensuring pipelines remain operational during the transition.
- Assess the Existing ETL Landscape
Start by cataloging existing ETL jobs, dependencies, and data sources. Understanding how pipelines interact is critical for planning migration order and identifying shared components.
- Prioritize Pipelines for Migration
Not all jobs need to move at once. Many teams begin with high-cost or high-compute workloads, where serverless execution can deliver the fastest benefits.
- Convert Pipelines to PySpark
ETL workflows are translated into PySpark code that can run within AWS Glue. This step may be done manually or using automation tools that extract transformation logic from legacy platforms.
- Validate Data Outputs
Before replacing legacy pipelines, teams run parallel executions to confirm that migrated jobs produce consistent results.
- Optimizeand Scale
Once pipelines are validated, organizations can optimize Spark execution, adjust resource allocation, and scale workloads within AWS Glue’s serverless environment.
Following a structured migration path helps organizations modernize ETL environments without disrupting existing data pipelines.
EZConvertETL for Automated ETL Migration
To address the scale and complexity of ETL modernization, automation is becoming a key part of migration strategies. EZConvertETL is a cloud-agnostic accelerator designed to convert legacy ETL pipelines into optimized PySpark workflows.
Instead of manually rewriting jobs built in legacy ETL platforms, EZConvertETL analyzes pipeline logic, maps dependencies, and generates equivalent PySpark code that can run on modern cloud platforms such as AWS Glue.
How EZConvertETL Converts Legacy ETL Pipelines to PySpark
Migrating ETL workloads from legacy platforms to modern frameworks like Apache Spark often requires translating complex graphical workflows into executable code. EZConvertETL accelerates this process by automatically converting legacy ETL logic into PySpark pipelines that can run on cloud platforms such as AWS Glue.
The conversion process typically involves four key steps.
- Metadata Extraction
EZConvertETL connects to legacy ETL platforms such as Informatica and Talend, to extract pipeline metadata. This includes mappings, transformations, workflow structures, and source–target relationships.
- Transformation Mapping
Each ETL transformation is analyzed and mapped to its equivalent operation in Spark. For example, filters, joins, aggregations, and lookups from legacy tools are translated into corresponding PySpark DataFrame operations.
- Automated PySpark Code Generation
Based on the extracted metadata and mapped transformations, EZConvertETL generates PySpark code that replicates the original ETL logic. The generated pipelines are structured for execution in environments such as AWS Glue.
- Validation and Optimization
After conversion, teams validate data outputs to ensure the new pipelines produce results consistent with the original workflows. Engineers can then fine-tune performance and resource configurations for production workloads.
By automating much of the translation process, EZConvertETL helps organizations reduce the time and effort required to migrate large ETL estates while maintaining the integrity of existing data pipelines.
Supported ETL Platforms for Automated Migration
EZConvertETL supports automated migration from several widely used enterprise ETL platforms by converting their workflows into PySpark pipelines that can run on modern data processing environments such as AWS Glue.
Common migration scenarios include:
- Informatica PowerCenter → PySpark / AWS Glue
- Talend Data Integration → PySpark / AWS Glue
- IBM InfoSphere DataStage → PySpark / AWS Glue
- SQL Server Integration Services → PySpark / AWS Glue
By automating pipeline conversion, EZConvertETL helps organizations modernize large ETL estates while reducing the manual effort required during migration.
Making ETL Migration Economically Viable
For many enterprises, legacy ETL platforms still power critical data pipelines. These tools played an important role in early data warehouse architectures, but their licensing models and infrastructure requirements can become increasingly expensive as data volumes grow.
Modern processing frameworks like Apache Spark running on AWS Glue offer a different operating model, serverless compute, elastic scaling, and usage-based pricing aligned with actual workloads.
The real challenge for many organizations isn’t recognizing the benefits of modernization; it’s executing ETL migration at scale. Large ETL estates, hidden dependencies, and manual pipeline rewrites can slow down transformation efforts.
By approaching migration with a structured strategy, and leveraging automation where possible, organizations can gradually transition legacy pipelines into modern, cloud-native architectures while controlling costs and operational risk.
Planning to reduce ETL costs and modernize legacy pipelines?
See how automated Talend to AWS Glue migration eliminates licensing overhead and accelerates cloud adoption.
WIT Leader
Data Team
Builds secure, governed data platforms that power analytics and feed AI models with clean, real-time, and high-quality data.
View all my PostsRelated Posts


















- Blog
- Automated BI Migration
- Conversational Analytics
Automated BI Migration: Moving Tableau and Powe...
-
24 Apr 2026
-
10 min read


- Blog
- Azure
- Databricks
Enabling Near Real-Time Operational Decision-Ma...
-
24 Feb 2026
-
5 min read
















- Blog
- Advanced Analytics
- Healthcare
Computer Vision for Health: Living Longer
-
07 Jul 2025
-
16 min read


- Blog
- Amazon Quicksight
- BI Reporting & Visualizations
5 Major Benefits of Amazon Quick Suite That you...
-
28 May 2025
-
3 min read



- Blog
- Amazon Quicksight
- BI Reporting & Visualizations
Tips and Tricks to Get the Most Out of Amazon Q...
-
07 May 2025
-
4 min read

- Blog
- Data Governance
- Healthcare
Rethinking Healthcare Data Governance: From Sil...
-
05 May 2025
-
3 min read

- Blog
- Data Management
- Healthcare
Building the Future of Healthcare Through Flawl...
-
02 May 2025
-
4 min read

- Blog
- Environmental Social & Governance (ESG)
Leveraging AI to Optimize Energy Consumption of...
-
30 Apr 2025
-
18 min read

- Blog
- Advanced Analytics
- Predictive Modeling
Predicting the Unpredictable: Leveraging AI to ...
-
11 Apr 2025
-
3 min read

- Blog
- Demand Forecasting
- Retail
The AI Storefront: How Retail and CPG Leaders C...
-
28 Mar 2025
-
2 min read

- Blog
- Advanced Analytics
When and Where GenAI Actually Makes Sense in Kn...
-
28 Mar 2025
-
16 min read


- Blog
- Advanced Analytics
- Retail
Navigating Ethical Issues of AI in Retail
-
12 Mar 2025
-
4 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
How Generative AI is Transforming Retail Custom...
-
12 Mar 2025
-
5 min read


- Blog
- Data Governance
Back to Basics: Essentials for Product Developm...
-
20 Feb 2025
-
23 min read


- Blog
- Advanced Analytics
- Generative AI & LLM
How Text Analytics and Generative AI Are Unlock...
-
09 Jan 2025
-
5 min read

- Blog
- BI Reporting & Visualizations
- Business Intelligence & Insights
Transforming BI Reporting and Visualization Wit...
-
06 Jan 2025
-
5 min read

- Blog
- Cloud Infrastructure Modernization
- Platform Management
Mastering Cloud Cost Optimization for a More Ef...
-
03 Jan 2025
-
5 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
How Generative AI is Transforming the Retail Ex...
-
20 Dec 2024
-
21 min read

- Blog
- Advanced Analytics
Preparing your Business for an AI-Driven Future
-
19 Dec 2024
-
10 min read

- Blog
- Advanced Analytics
What it Means to be Human in the Age of AI
-
12 Dec 2024
-
18 min read

- Blog
- Business Intelligence & Insights
- Reporting Modernization
How EZConvertBI Simplifies Your Looker Migration
-
12 Dec 2024
-
4 min read

- Blog
- Advanced Analytics
- Business Intelligence & Insights
Transforming Business Intelligence with Looker
-
12 Dec 2024
-
6 min read

- Blog
- Advanced Analytics
- Data Governance
Key Challenges in AI Adoption for Businesses
-
11 Dec 2024
-
13 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
What AI Disruption Means for Businesses
-
05 Dec 2024
-
15 min read

- Blog
- Advanced Analytics
- Business Intelligence & Insights
Optimizing Your Cloud Data Platform with Google...
-
04 Dec 2024
-
7 min read

- Blog
- Advanced Analytics
- Amazon Quicksight
From Shopfloor to Boardroom: Get Your Data to T...
-
21 Nov 2024
-
5 min read

- Blog
- BI Reporting & Visualizations
- Build & Migrations
Let Your Data Speak to You – Unlocking Organiza...
-
12 Nov 2024
-
5 min read

- Blog
- Advanced Analytics
- Business Analytics
The Joy of Decision-Making and Why It Matters
-
12 Nov 2024
-
5 min read

- Blog
- Data Management
- Strategy & Assessments
Understanding Data Products
-
11 Nov 2024
-
4 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
Crafting User-Focused Solutions and Building an...
-
06 Nov 2024
-
12 min read

- Blog
- Architecture & Engineering
- Cloud Infrastructure Modernization
How Data Mesh is Shaping the Future of Data Man...
-
05 Nov 2024
-
8 min read

- Blog
- Business Intelligence & Insights
- Reporting Modernization
Streamline your Power BI Migration with EZConve...
-
22 Oct 2024
-
4 min read

- Blog
- Advanced Analytics
Maximizing Business Transformation Through AI a...
-
15 Oct 2024
-
18 min read

- Blog
- Advanced Analytics
- BI Reporting & Visualizations
How Gen AI and Microsoft Copilot are Reshaping ...
-
03 Oct 2024
-
5 min read

- Blog
- Advanced Analytics
- Build & Migrations
Transforming Data Capabilities by Moving Beyond...
-
25 Sep 2024
-
5 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
How to Build a Restaurant Performance Measureme...
-
24 Sep 2024
-
6 min read

- Blog
- Advanced Analytics
- Business Analytics
Leveraging Data Science and AI to Drive Innovat...
-
16 Sep 2024
-
16 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
The Role of Mature Data and AI in Accurate Gene...
-
26 Aug 2024
-
14 min read

- Blog
- Advanced Analytics
- Business Analytics
Listening to the Voice of the Customer: A Key t...
-
21 Aug 2024
-
6 min read

- Blog
- Azure
- BI Reporting & Visualizations
Moving from Tableau to Power BI: Why Companies ...
-
20 Aug 2024
-
6 min read

- Blog
- Advanced Analytics
How AI Impacts the Ways We Develop and Grow Dat...
-
14 Aug 2024
-
18 min read

- Blog
- Advanced Analytics
- Demand Forecasting
How to Use Demand Forecasting to Improve Busine...
-
12 Aug 2024
-
6 min read

- Blog
- Business Intelligence & Insights
- Cloud Infrastructure Modernization
Building a Data Platform on Snowflake
-
01 Aug 2024
-
5 min read

- Blog
- Advanced Analytics
- Demand Forecasting
Why Your Demand Forecasting Model Doesn’t Work ...
-
30 Jul 2024
-
7 min read

- Blog
- Advanced Analytics
- Data Governance
Expert Insights on Demonstrating the Value of D...
-
22 Jul 2024
-
9 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
How to Effectively Harness Gen AI for Your Busi...
-
18 Jul 2024
-
5 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
Navigating the AI Hype Cycle by Setting Realist...
-
11 Jul 2024
-
15 min read

- Blog
- Advanced Analytics
- Data Management
Leveraging AI Technology in Healthcare
-
10 Jul 2024
-
17 min read

- Blog
- Advanced Analytics
- Data Governance
Expert Insights on Leveraging Data Quality and ...
-
01 Jul 2024
-
8 min read

- Blog
- Data Governance
- Privacy Governance & Compliance
Choosing the Right Data Governance Approach for...
-
24 Jun 2024
-
5 min read

- Blog
- Data Governance
- Privacy Governance & Compliance
Expert Insights on Leveraging Data Governance f...
-
11 Jun 2024
-
12 min read

- Blog
- Data Governance
- Data Management
The Role of Existing Data Stewards in Driving G...
-
10 Jun 2024
-
3 min read

- Blog
- Data Governance
- Data Management
Optimizing Data Governance Programs Beyond Chec...
-
03 Jun 2024
-
4 min read

- Blog
- Data Governance
- Privacy Governance & Compliance
Measuring Data Governance Progress With Metrics...
-
29 May 2024
-
4 min read

- Blog
- Data Governance
- Data Management
Decoding Data Governance: Going Beyond its Name
-
22 May 2024
-
5 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
How Your Data Governance Strategy Supports Data...
-
15 May 2024
-
4 min read

- Blog
- Data Governance
- Privacy Governance & Compliance
The Need for Data Governance in a Changing World
-
13 May 2024
-
4 min read

- Blog
- Manufacturing
How Smart Manufacturing and Digital Twins Are H...
-
06 May 2024
-
6 min read

- Blog
- Advanced Analytics
- Data Management
Crafting a Data Strategy to Support AI in Healt...
-
30 Apr 2024
-
13 min read

- Blog
- Data Management
- Data Privacy & Regulatory Compliance
How to Achieve Compliance Excellence in Healthc...
-
24 Apr 2024
-
5 min read


- Blog
- Environmental Social & Governance (ESG)
- Manufacturing
Modernizing Supply Chains for Resilience and Su...
-
17 Apr 2024
-
8 min read

- Blog
- Advanced Analytics
- Business Analytics
Getting the Absolute Best Data Science Talent t...
-
16 Apr 2024
-
14 min read

- Blog
- Architecture & Engineering
- Data Management
How to Design a Modern Data Architecture
-
10 Apr 2024
-
5 min read

- Blog
- Advanced Analytics
- Predictive Modeling
How to Re-imagine Customer Experience With Pred...
-
10 Apr 2024
-
4 min read

- Blog
- Advanced Analytics
- Generative AI & LLM
Expert Insights on Transformative AI Strategies...
-
10 Apr 2024
-
13 min read

- Blog
- Data Management
- Strategy & Assessments
Why Your Organization Needs a Data Strategy
-
01 Apr 2024
-
4 min read

- Blog
- Data Management
- Strategy & Assessments
Getting Started With Data Strategy: The AI-Led ...
-
28 Mar 2024
-
3 min read

- Blog
- Cloud Infrastructure Modernization
- Cloud Security & Monitoring
The Role of AI and ML in Cloud Security Monitoring
-
21 Mar 2024
-
4 min read

- Blog
- Data Management
- Strategy & Assessments
Getting Started With Data Strategy: The Acceler...
-
20 Mar 2024
-
4 min read

- Blog
- Advanced Analytics
The Role of the Chief AI Officer (CAIO)
-
15 Mar 2024
-
13 min read

- Blog
- Data Management
- Strategy & Assessments
Getting Started With Data Strategy: The Traditi...
-
13 Mar 2024
-
4 min read

- Blog
- Healthcare
- Strategy & Assessments
How Building a Strong Data Strategy Boosts Heal...
-
12 Mar 2024
-
7 min read

- Blog
- Data Management
- Strategy & Assessments
The Do’s and Don’ts of Data Strategy
-
06 Mar 2024
-
6 min read

- Blog
- Advanced Analytics
- Manufacturing
The Role of Advanced Analytics and AI in Reduci...
-
04 Mar 2024
-
5 min read

- Blog
- Advanced Analytics
- Data Management
Reducing Barriers to Complex Data Science Entry...
-
15 Feb 2024
-
14 min read


- Blog
- Amazon Quicksight
- AWS
Mastering the Art of Visual Storytelling: Wavic...
-
29 Jan 2024
-
1 min read

- Blog
- Amazon Quicksight
- AWS
Getting to Know the Tableau-to-Amazon Quick Sui...
-
29 Jan 2024
-
3 min read

- Blog
- Manufacturing
Manufacturing Metrics That Elevate Performance ...
-
24 Jan 2024
-
8 min read

- Blog
- Restaurant
Mastering the Increasingly Complex QSR Landscape
-
18 Jan 2024
-
3 min read

- Blog
- Advanced Analytics
- Manufacturing
Manufacturing in 2024: Key Data and Analytics T...
-
12 Dec 2023
-
8 min read

- Blog
- Advanced Analytics
- Business Analytics
Data-Driven Dining: Three Essential Data, Analy...
-
20 Nov 2023
-
7 min read

- Blog
- Healthcare
2024 Healthcare Trends: Reimagining the Industr...
-
14 Nov 2023
-
6 min read

- Blog
- Advanced Analytics
- Business Analytics
Demystifying Data and Analytics
-
24 Oct 2023
-
12 min read

- Blog
- Healthcare
Exploring Data and Analytics in Healthcare: A Q...
-
12 Oct 2023
-
7 min read


- Blog
- Advanced Analytics
- Predictive Modeling
Revolutionizing Your Customer Experience Measur...
-
04 Oct 2023
-
10 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
How Integrating Reservation and POS Data Can Pr...
-
27 Sep 2023
-
4 min read

- Blog
- Advanced Analytics
- Business Intelligence & Insights
Next-Generation CDOs: A Conversation About the ...
-
25 Sep 2023
-
12 min read

- Blog
- Data Management
How Effective Data Management Helps to Realize ...
-
22 Sep 2023
-
6 min read

- Blog
- Business Intelligence & Insights
Why Data Analytics Projects Fail and How to Ove...
-
22 Sep 2023
-
5 min read

- Blog
- Advanced Analytics
- Machine Learning & MLOps
How to Build Resilient Business Strategies Usin...
-
22 Aug 2023
-
6 min read

- Blog
- Business Analytics
- Manufacturing
3 Ways Data Analytics Can Transform Your Supply...
-
01 Aug 2023
-
4 min read

- Blog
- Business Analytics
- Manufacturing
How is Data Analytics Transforming Production?
-
26 Jul 2023
-
5 min read

- Blog
- Advanced Analytics
- Predictive Modeling
5 Blockers to Effective Artificial Intelligence...
-
24 Jul 2023
-
6 min read

- Blog
- Data Governance
- Data Management
Instilling Data Quality Into Your Data Manageme...
-
20 Jul 2023
-
7 min read

- Blog
- Advanced Analytics
- Business Analytics
3 Ways Engineers Can Drive Business Value with ...
-
18 Jul 2023
-
4 min read

- Blog
- Advanced Analytics
- Predictive Modeling
Calculating ROI for Advanced Analytics Initiatives
-
15 Jul 2023
-
6 min read

- Blog
- Data Management
- Strategy & Assessments
How Business Leaders Leverage Data as a Critica...
-
15 Jun 2023
-
7 min read

- Blog
- Amazon Quicksight
- BI Reporting & Visualizations
Clear and Actionable: Wavicle’s Winning Dashboard
-
09 May 2023
-
2 min read

- Blog
- Cloud Infrastructure Modernization
- Platform Management
The Importance of Effective Cloud Platform Mana...
-
07 May 2023
-
4 min read

- Blog
- Data Management
How Businesses Benefit from Modern Data Managem...
-
02 May 2023
-
7 min read

- Blog
- Architecture & Engineering
- Data Management
Data Architecture 101: Trends and Terms to Know
-
25 Apr 2023
-
6 min read

- Blog
- Restaurant
Building a Contact-Free Smart System
-
20 Apr 2023
-
2 min read


- Blog
- Build & Migrations
- Data Management
Which Data Storage Solution is Right for Your O...
-
04 Apr 2023
-
6 min read

- Blog
- Manufacturing
What’s Next in Manufacturing? A Q&A With T...
-
02 Mar 2023
-
4 min read


- Blog
- Data Governance
Governing Your Data: How to Start Designing a G...
-
14 Feb 2023
-
3 min read

- Blog
- Data Governance
Data Governance Roles: Who Should Govern Your D...
-
07 Feb 2023
-
4 min read

- Blog
- Financial Services
Financial Services Executive Outlook: The Benef...
-
02 Feb 2023
-
3 min read

- Blog
- Financial Services
Financial Services Executive Outlook: The Path ...
-
26 Jan 2023
-
4 min read

- Blog
- Data Governance
The Path to Data Governance: What Data Will Be ...
-
24 Jan 2023
-
3 min read

- Blog
- ActiveInsights
- Advanced Analytics
The Future of Voice of Customer: 5 Trends to Watch
-
18 Jan 2023
-
8 min read

- Blog
- Financial Services
Financial Services Executive Outlook: Capitaliz...
-
12 Jan 2023
-
4 min read

- Blog
- Data Governance
What is a Customer? How Simple Questions Get Co...
-
05 Jan 2023
-
6 min read

-
29 Nov 2022
-
7 min read


- Blog
- Data Governance
- Data Privacy & Regulatory Compliance
Why a Good Governance, Privacy, and Compliance ...
-
08 Nov 2022
-
7 min read


- Blog
- Data Governance
Data Governance for Business Leaders: 3 Concept...
-
25 Oct 2022
-
5 min read



- Blog
- Financial Services
Financial Services Executive Outlook: The Impac...
-
29 Sep 2022
-
2 min read


- Blog
- Financial Services
Financial Services Executive Outlook: The Reali...
-
22 Sep 2022
-
3 min read







- Blog
- Augment
- AWS
ETL Modernization: Reduce Migration Timelines a...
-
02 Mar 2022
-
4 min read

- Blog
- Advanced Analytics
- Machine Learning & MLOps
Five Steps To Operationalizing Advanced Analyti...
-
24 Nov 2021
-
5 min read

- Blog
- Augment
- Data Privacy & Regulatory Compliance
A New Way to Quickly and Easily Discover PII Da...
-
19 Oct 2021
-
2 min read

- Blog
- Architecture & Engineering
- Augment
6 Reasons You Need an Augmented Data Quality So...
-
16 Sep 2021
-
5 min read

- Blog
- ActiveInsights
- Business Analytics
Ditch the Survey and Really Get to Know Your Cu...
-
15 Jul 2021
-
8 min read

- Blog
- Architecture & Engineering
- Business Analytics
Five Reasons Why Boutique Consulting Firms Are ...
-
21 Jun 2021
-
6 min read
- Blog
- Advanced Analytics
- Machine Learning & MLOps
Deep Multi-Input Models Transfer Learning For I...
-
14 Jun 2021
-
15 min read

- Blog
- Advanced Analytics
- Machine Learning & MLOps
Deep Learning For Natural Language Processing o...
-
08 Jun 2021
-
9 min read

- Blog
- ActiveInsights
- Customer 360
5 Ways to Successfully Win Travelers’ Loy...
-
25 May 2021
-
6 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
Want to Meet Consumer Expectations? Demand Fore...
-
25 May 2021
-
9 min read

- Blog
- Advanced Analytics
- Customer 360
These 3 Top Retail Analytics Trends are Revolut...
-
25 May 2021
-
7 min read

- Blog
- Demand Forecasting
Demand Forecasting Is Always Wrong: Three Ways ...
-
27 Apr 2021
-
5 min read

- Blog
- Architecture & Engineering
- Business Analytics
8 CDOs Share Key Insights on How to Build a Suc...
-
23 Apr 2021
-
6 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
Here’s Why 2021 is Actually the First “Year of ...
-
07 Apr 2021
-
10 min read

- Blog
- Advanced Analytics
- Business Analytics
Five Critical Elements For Successful Customer ...
-
17 Feb 2021
-
5 min read

- Blog
- Architecture & Engineering
- Business Analytics
Everything You Need to Know About Data & A...
-
15 Jan 2021
-
5 min read

- Blog
- Business Intelligence & Insights
- Data Management
What Happens When Insurers Turn to Data Analytics?
-
04 Jan 2021
-
4 min read

- Blog
- Architecture & Engineering
- Data Management
What Happens When ERP Systems Talk? The Results...
-
04 Jan 2021
-
5 min read

- Blog
- Data Management
- Data Privacy & Regulatory Compliance
Compliance Data Management: the Case For Automa...
-
02 Dec 2020
-
5 min read

- Blog
- Architecture & Engineering
- Data Management
Compliance Data Management: Data Preparation Sa...
-
02 Dec 2020
-
7 min read

- Blog
- Business Analytics
- Customer 360
Your Customers Like You, They Really, Really Li...
-
25 Aug 2020
-
9 min read

- Blog
- Predictive Modeling
- Restaurant
Why Micro-Segmentation Matters in a Post-COVID ...
-
10 Aug 2020
-
6 min read

- Blog
- Architecture & Engineering
- Data Management
Data Architecture From Right to Left: Start Wit...
-
18 May 2020
-
6 min read

- Blog
- Business Analytics
- Business Intelligence & Insights
Using Big Data to Better Predict Your Recovery:...
-
11 May 2020
-
8 min read



- Blog
- Cloud Infrastructure Modernization
- Data Management
How to Get Faster, More Reliable Analytics from...
-
04 Dec 2019
-
7 min read

- Blog
- ActiveInsights
- Architecture & Engineering
Take Ownership of the Relationship with Your Di...
-
04 Dec 2019
-
4 min read

- Blog
- ActiveDeliver
- Business Intelligence & Insights
Food Delivery: Who Owns the Customer?
-
05 Nov 2019
-
5 min read



- Blog
- Business Analytics
- Business Intelligence & Insights
Quick Service Restaurants are Ravenous for Big ...
-
03 Apr 2019
-
4 min read

- Blog
- Architecture & Engineering
- Data Management
CDO Summit Key Takeaways
-
02 Apr 2019
-
7 min read

- Blog
- Advanced Analytics
- BI Reporting & Visualizations
2019 Business Intelligence Trends
-
16 Oct 2018
-
3 min read






